

ElectionGPT Predicts Harris to get between 306 and 316 electoral college votes (September 25th)
ElectionGPT Predicts Harris to get between 306 and 316 electoral college votes (September 25th)

In this substack, I want to update on yesterday’s ElectionGPT results. Which already are delayed by two days because they are based on the news we pulled for the day before yesterday (meaning news up through Tuesday). The shiny app is here.
Review of the methodology
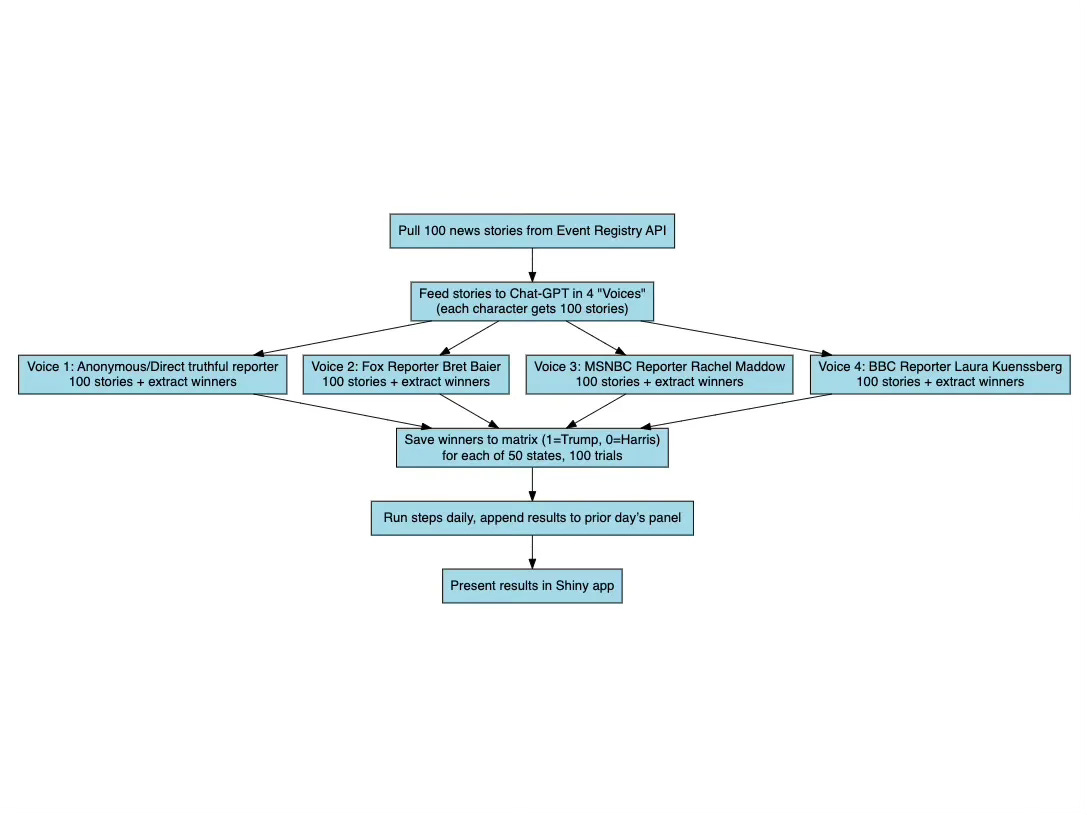
The methodology recall for this forecasting approach is show above. First, this is based on earlier work of mine with Van Pham in which we tried to understand if “mimicking intelligent speech through storytelling” might force ChatGPT-4’s base model to access its training data in a way that it forecast events that it found sensible. It’s a conjecture and it may be off base, but that’s the conjecture.
We chose “future narratives” – stories about events set in the future after the events happened – because we wanted to better understand if the transformer architecture did something different when asked to predict than when it simply stated things conversationally. Plus, we had reason to believe it would not predict anyway, and we showed it wouldn’t. Most of the time it refused, but if it didn’t refuse, results were spread over many more options.
This suggests that there is a degree randomness in ChatGPT-4 in addition to stubborn refusal to play along. So, in addition to the future narrative where technically ChatGPT-4 was no longer predicting but simply tell an intelligible story similar to how someone in the future would tell that story (using its training data to fill in the details), we wanted to use a monte carlo approach to get a central tendency and a distribution of answers under the assumption that the errors are random and thus cancel out in large samples. We are still working with a small sample, though – we only ask the same prompt 100 times. Future work will increase that, but for now it is only 100 due largely to budget constraints as at 100 trials for all 50 states for 4 different “journalists” who are announcing the winner of the 2024 election (i.e., independent and trustworthy reporter, Brett Baier from Fox News, Rachel Maddow from MSNBC, Laura Kunnesberg from BBC), we are at 20,000 observations per day, and now at around $4/day using various APIs (GPT-4o turbo and GPT-3.5 are the ones we pay for).
Swing states
Now I want to share some observations. Let me announce the current winner, by voice, and then offer some descriptions of what is going on in our ElectionGPT simulation. Keep in mind that while the shiny has September 25th (Wednesday) as the date, most of these news reports come from September 24th (Tuesday). So it’ll be the 25th date on the graph, but the news mostly (but not entirely) comes from the 24th because we run the simulation early morning (around 1-2am CST).
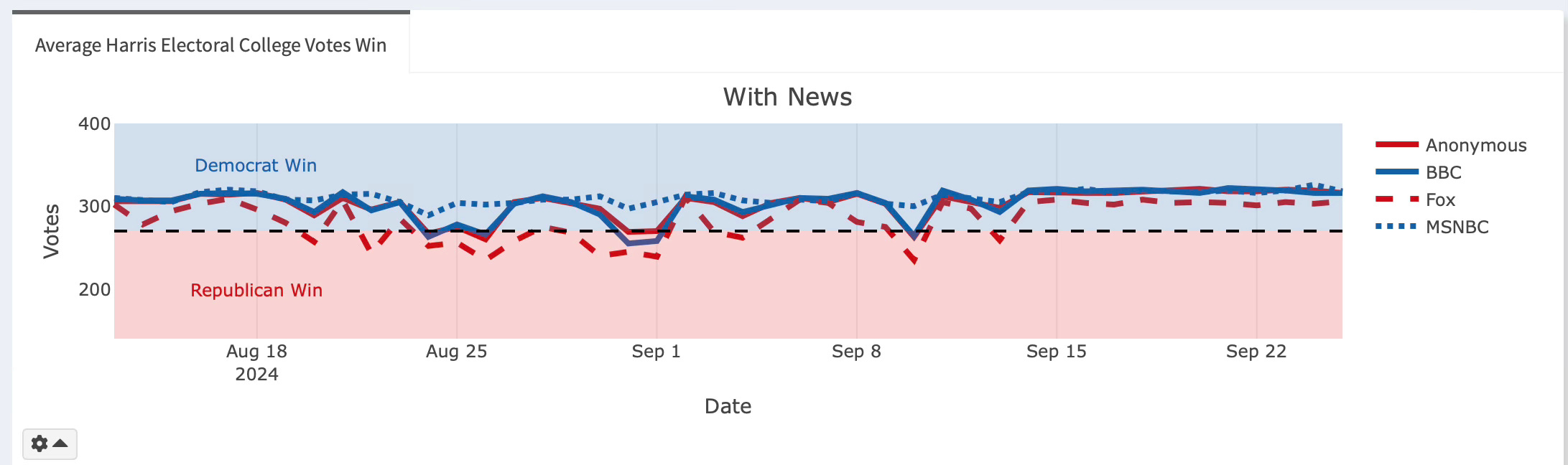
Independent, trustworthy reporter (anonymous): 316 electoral college (EC) votes
Fox: Harris wins with 306 EC votes
BBC: 316 EC votes
MSNBC: 318 EC votes
The national time series plots have been this way roughly ever since September 14th. Before that, the predictions had varied a little. Fox had called it for Trump 12 times since August 13th, when we started this. And the other voices just a few times. But ever since September 14th, Harris has been on a run because even Fox has her winning handily by 30-36 votes. Why is this going on? Why has it suddenly been the case that there’s stability in the time series?
No News Baseline
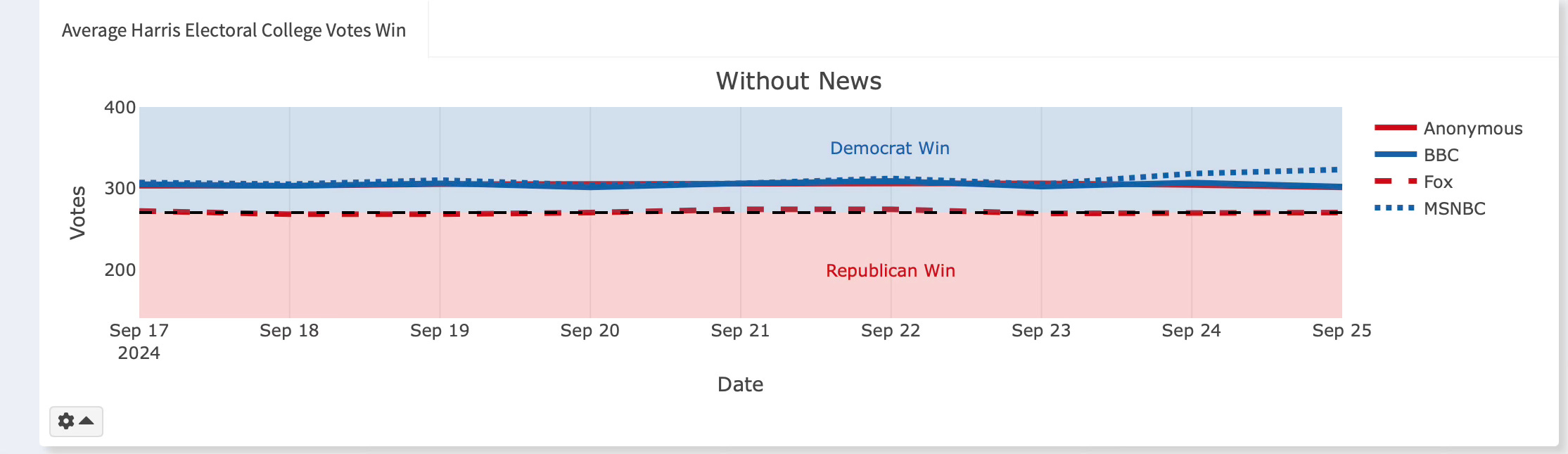
We do this simulation in two ways – we have a forecast where the journalists make their announcement after we submitted a large sample of articles (100 summaries plus headline plus the source) to the GPT-4o turbo API. But we also had them just announce their winners in a head to head contest between Harris and Trump using only the October 2023 training data date cutoff. And if you look at that, you can see that it’s been flat pretty much the entire time, but with a level difference between Fox news – where it's been a coin flip with Harris winning 270 EC votes – and everyone else which has been between 300-320 give or take. So the main thing to note here is that without any updating, each mean forecast is mostly the same, though it can change a little as sometimes we cannot give a full set of 100 trials. Because we have pre-registered, we only fix major problems, and have been leaving the failures to complete a full 100 trials. It’s usually around 90, but it can vary. Later we will dig into each element that could be driving forecasting variation, but for now just note this: that Fox and the others are always around 30-50 votes apart without any news.
So, what is immediately interesting is that the news is causing a convergence in the announcements. Fox has shifted up to 306 votes, but the others are 316 to 318. So the margin between Fox and the others has narrowed. We don’t know yet what precisely in the 100 articles seems to be doing this as that’s the next step for us now that we have a stable semi-automated procedure. We just know that sometimes the gap narrows between Fox and MSNBC (conservative to liberal bands).
Swing States Are Swinging Less
So, why is there stability in the daily predictions? Without getting into the core mechanism, which has to be in the text itself, the mechanical reason is that the 7 swing states have stopped swinging.




There are thought to be 7 current swing states: Arizona, Georgia, Michigan, Nevada, North Carolina, Pennsylvania, Wisconsin. And what is basically happening is the swing states have in large part stopped swinging. They’ve all shifted, even for Fox, to Harris on average across our approximately 100 daily trials. Those four voices average announcements of the winner by day for each of the seven swing states is listed in the image gallery directly above.
Fox without any news typically had Trump winning Georgia and Wisconsin in about 1-5% of the trials. But now Georgia is winning over 80% of the time in our trials, and Wisconsin over 90%. Put aside whether it’s “true” – it’s a forecast, so it cannot be literally true. We won’t know anything about its accuracy for another 5 ½ weeks. My point is much narrower than that – the news, whatever is in it, is pushing up all of the swing states since September 14th. The marginal state in the distribution of swing states has been North Carolina, but it’s been just a tad bit for Trump (at its lowest Harris was winning a little under 50% of the time across the trials). But more recently, even it seems to be growing.
Conclusion
Something is going on in the simulation related to the news. We won’t know what that is for a while as it’s still a bit of a juggling act to ensure data quality on a daily basis. But what I can say is this. The swing states have stopped swinging in the simulation for almost two weeks now. Something seems to happen in the news starting September 14th that pushed them all above 50% for Harris and that’s created national stability in the daily EC votes predictions. So that’s one thing.
Second, the gap between Fox and the others has shrunk. The gap without any news is large – between 30-50 EC votes will separate Fox and the others. Fox using only its October 2023 training data has Trump winning head to head against Harris in our narratives with 270 votes. But now not only does with news Harris win consistently, the overall gap has shrunk from 30-50 EC votes to around 10-12.
And last, the news. I’m not going to say that GPT-4o turbo is literally Bayesian updating because I don’t know that. Bayesian updating is a technical formula, and I don’t know that it’s doing that because we have no idea what even “priors” mean here. I mean, we do in a sense if you want to interpret the share of trials that go to one or the other as a probability, but we don’t know that. But fine – treat GPT-4o turbo’s central tendency in the data as a prior if you want. It is based on the October 2023 training data date cutoff as it has no information past that. And then treat the news as a signal. Then the posterior mean EC is going up as a result of the signal – with all caveats about false positives, which I haven’t thought about much yet as I haven’t given myself permission yet to go that route. But I will say is that metaphorically, Bayesian updating might be as close to a conceptual framework for thinking about this step by step movement from some base “belief” to some posterior “belief” based on “reading the news”.
So next steps is to, as I said, start the natural language processing. We have sentiment scores on each news article. But there are 100 articles. We feed all 100 articles into GPT-4o turbo and then we get a single announcement at the state level. We haven’t yet decided the specification for that as it’s not 1 signal per 1 prediction. It’s 100 signals per 50 state predictions and for 4 separate voices. We don’t have to aggregate to the 100 trials and get a mean, but it is technically the same X variable (e.g., 100 newspaper articles), and so I just need to think through the data structure and the regression and the standard error construction for this. But point is, we do have news article sentiment scores at the trial level, we have 4 voices making 50 announcements per trial. Maybe we cluster by day-voice? Not sure, but the dataset will be massive if the observation is something like a distribution of sentiment scores and maybe counting particular words. We’re all reading about NLP and trying to think of the most transparent and yet informative first stab.