


I talked with two editors this week and it got me thinking of something straightforward that could be done that doesn’t seem terribly controversial. So what I’m going to do in this post is lay that out, with some pretty pictures, and some math to make a point. This is related to a post I wrote a couple weeks ago. Only this time I’m going to say that if Claude Code helps economists complete their manuscripts faster, then it’s borderline impossible that we don’t see swells in higher rates of submissions at journals and therefore more refereeing per person.

Thanks again for supporting the substack and the podcast! It’s a lot of fun talking about causal inference and AI, particularly Claude Code. If you aren’t a paying subscriber, consider becoming one so you can read an ungodly number of old posts about difference-in-differences, causal inference and AI, including my Claude Code series, all of which is behind the paywall! All new Claude Code posts are free, but go behind the paywall after four days, so continue stopping by for the free content too!
Claude Code and Bathtubs
Derek Neal and Armin Rick wrote a paper about prisons. The US incarceration rate rose from about 160 per 100,000 in the early 1970s to over 500 per 100,000 by 2008. The prison population tripled. People treated this as a sociological puzzle. It went by terms like mass incarceration, the new Jim Crow, and has been considered a uniquely American pathology. And there are deep economic and sociological stories to tell. But Neal and Rick’s paper contains also a very simple arithmetic insight which is that the extending sentences must cause the stock of prisoners to grow even if you never increase the arrest rate or the conviction rate. In other words, longer sentences are enough to blow up the country’s incarceration rate.
Think of the prison system as a bathtub. Water flows in through the faucet and exits through the drain. The faucet, the flow in, are admissions, which is a function of crime, arrests, convictions and sentences upon conviction. Water flows out through the drain which is prison releases and that includes people finishing their sentences as well as early release through parole. The water level in the tub is the prison population and in equilibrium, given fixed prison capacity, when admissions and releases were equal, the prison population did not change beyond some manageable fluctuations here and there.
So, what if you were to increase the rate of water entering the bathtub, perhaps by widening the faucet. In our situation that would mean arresting more people but holding conviction rates fixed. Then you’d have more convictions, more flow. But another way you could do it is with tougher sentencing, meaning increase the conviction rate for the same group of arrestees. And yet still one more mechanism is hold arrest rates the same and conviction rates the same, but extend the sentence for virtually every crime by several years.
Neal and Rick imply that the last mechanism — longer sentences — was responsible for the prison population per capita to rise by as much as it did in American history and in such a short period of time. And since it was precisely longer sentences, it nearly mechanically forced the release rate to get tangled up in such a way that at a given period of time, there would have to be more prisoners in the prisons. You cannot increase the flow in through longer sentences and release them at the same rate per period since you are modifying the release rate per period by extending the sentence length.
And so as such, the stock-flow identity they propose in which the stock tomorrow equals the stock today plus the inflow minus the outflow states that this particular opening up the nozzle ended up both widening the flow in and kept the back end flat, causing the stock to rise, and that because this was an identity, it could not be otherwise.
I wrote my 2007 dissertation on the economic effects of mass incarceration on Black families and Black marriage markets, so the actual phenomena itself was not new to me when I read Neal and Rick. What was new for me was this explicit break down of stocks and flows, and the mathematical necessity of rising prison populations via one particular flow channel (longer sentences). For some reason, all of the mechanisms — higher arrest rates, higher conviction rates, longer sentences — were in my mind more or less identical. And to a degree they for sure are, no doubt. They all widen the flow in, but in principle you could simultaneously increase arrest rates and increase parole rates or even reduce sentences and therefore the increase in admissions and departures could cancel out and thus hold fixed the prison population. But the fact that longer sentences tied up the backend flow out has been something I’ve thought about a lot for a decade since I read the paper.
And now I am thinking about this stock-flow identity because I think academic journals are about to learn the same lesson whether Claude Code causes the market to have AI fully automated papers like what the Social Catalyst Lab is illustrating in Zurich, or if it simply makes economists more productive such that they each finish their papers faster. Either of these triggers increased flows, and since we have a fixed number of referees which cannot be expanded by AI, AI must increase the number of manuscripts per referee and manuscripts per journal. Which could threaten the system entirely.
Putting this out there for editors
As I said, this is related to an earlier post I wrote. Two weeks ago I laid out what happens when AI collapses the cost of producing a submission-quality manuscript. Submissions multiply. Publication slots don’t. Acceptance rates crash. It’s a prisoner’s dilemma — individually rational to scale volume, collectively destructive. You can read the full argument in Post 27.
Claude Code 27: Research and Publishing Are Now Two Different Things

Claude Code has made it easier to do research now. But it is about to get much harder to publish in traditionally valued locations.
But while this post is related, it is still somewhat different. Post 27 was the economic story about ceteris paribus technological shocks to supply curves due to marginal cost of production plummeting to zero, unchanging demand curves, and equilibrium. Fairly straightforward story you can plot out in a few moves using only generic knowledge of supply and demand.
But now I want to talk in this post is about the plumbing. Specifically the stock-flow identity. And I’m doing this because I don’t think you can argue with an identity as it’s not a model, not a theorem, and not a conjecture. It’s accounting and must hold therefore as a result.
And yet the post is actually still different because unlike post 27, this one is normative, not merely positive. It’s prescriptive, not merely descriptive. It contains as economists say “policy recommendations” around normative goals that I think could be the goals that unite all economists, even ones who oppose AI for research. And it is written for editor-in-chiefs, co-editors, associate editors and editorial boards to contemplate. I wanted to just put it out there as I thought it might be useful to help launch conversations internally at journals amidst themselves.
The stock-flow identity
First, let me write down the stock-flow identity from Neal and Rick and get that out of the way. It’s a dynamic identity where t is today.
S is the stock of papers currently under review at a journal. I is the inflow which are new submissions that to the desk. O is the outflow which in this case are editorial decisions at the desk, referee decisions, accept, reject, or R&R. The stock tomorrow, S+1, equals the stock today, t, plus what came in, I, minus what went out, O.
In steady state, inflow equals outflow and thus the stock settles at S* = I times D, where D is the average time a paper spends in the review process. That’s “Little’s Law” which is the same equation that governs hospital beds, highway traffic, and prison populations. In other words, it is Little’s Law applied to scientific manuscripts.
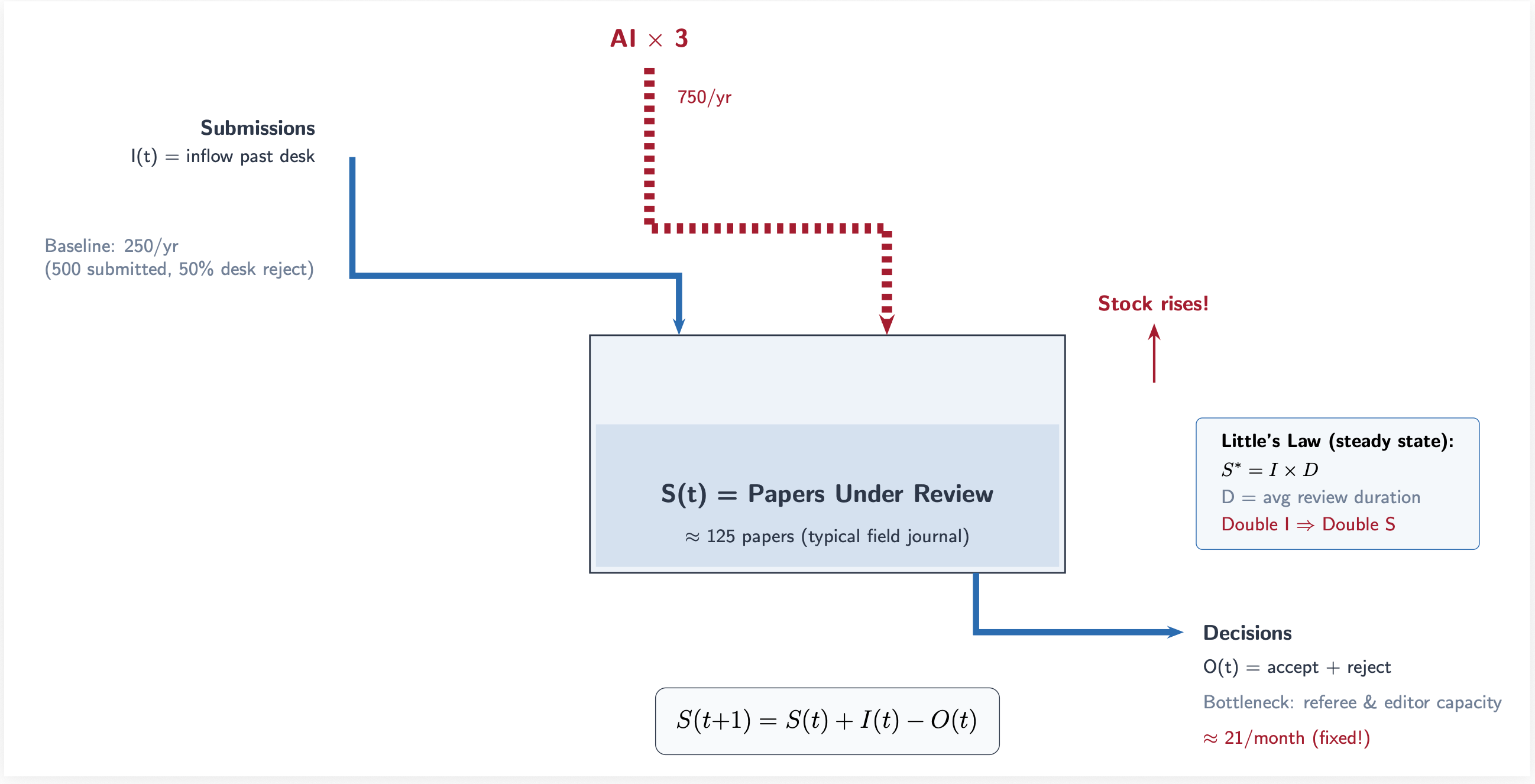
And herein lies the problem, if you want to call it a true problem: AI increases I. It does this through increased labor productivity. Economists, in this example, finish papers faster, causing them to write more papers, causing them to submit more papers at each time period.
But D is bottlenecked by referees. There are only so many of these humans and they take several weeks to several months to evaluate a paper unless AI speeds up that process too. And therefore O is bottlenecked by editors who are also humans who can only process so many decisions per week. So if I doubles and O stays flat, the stock must grow. This results in queuing. Wait times to hear back extend and/or acceptance rates fall. Editors are taxed via increased handling of submissions on a weekly basis, and so submissions per editor rises, and if they desk reject at the same rate, submissions per referee does as well. The denominator, in other words, remains fixed and quite frankly cannot go up without more PhDs being brought into economics, which editors and referees do not control, but rather is controlled by state budgets, university allocation of funds to economics departments, more faculty lines, and therefore a growth in the pool of faculty to edit journals and referee them as well. But the former requires more editors, which is a journal decision, and it ultimately doesn’t matter anyway as since each person is now submitting — not publishing, mind you, but submitting — at a higher rate, even the expansions still must bring in more papers per capita. The only thing you can do if I rises and you want the stock the same is desk reject at a higher rate, but even then that will not change the stock of submissions to the desk. Even if you reject more frequently at the desk, it won’t matter with respect to the stock of those manuscripts at the desk. Editors must be handling more manuscripts per capita if I rises. The only way you could increase submissions but maintain the same number of manuscripts at the desk is if there was some intermediate step between when an author submits their manuscript but something intervenes before it hits the desk — which makes absolutely no sense in this context, and therefore AI must mechanically put more papers into the mailbox of editors.
So, as I said, this is not a model at all. It is an identity, it will hold. The question is therefore what will the editors do in this situation because if they do nothing at all, it will simply pass along more work to referees, who are fixed, and it is unclear if you will have the same level of compliance because you honestly have heterogenous compliance now as it is. The same ones submitting at a higher rate, experiencing higher productivity, will still have to find a way to handle the increased inflow to them managing more papers per time period no matter how you slice it.
The numbers were already bad before AI showed up
Card and DellaVigna documented this in 2013. Submissions to the top-5 journals nearly doubled between 1990 and 2012 from about 3,000 to 6,000 per year. Over the same period, the number of articles those journals actually published fell from around 400 to 300. This led to acceptance rates collapsing from 15% to 6%.
Time from submission to publication doubled too. Ellison measured this in a 2002 JPE, and it’s only gotten worse since because papers are now three times longer than they were in the 1970s.
So here’s the part that matters for the AI argument. Conley and Onder in the JEL found that 90% of economics PhDs never publish even half a paper in top journals. You have Pareto laws governing the distribution of publication with the top 1% of publishing economists produce around 13% of all quality-adjusted research. The top 20% produce 80% which is the classic ratio for the so-called Pareto principle.
Let’s look at some of these numbers rearranged. Total submissions were rising from 1990 to 2010 (panel A) and under AI labor productivity, if predictions are even reasonably accurate, may lead to 2 to 5x that rate which is shown in the shaded pink region. Note that this is only for the top-5s, whereas my previous post had been about all the journals. Acceptances rates at the top 5 (panel B) has been falling already, and therefore that slope falls even more with AI under either conservative of aggressive scenarios. The rise in months from submission to publication continues growing (panel C) and therefore the bottleneck occurs without any change (panel D).
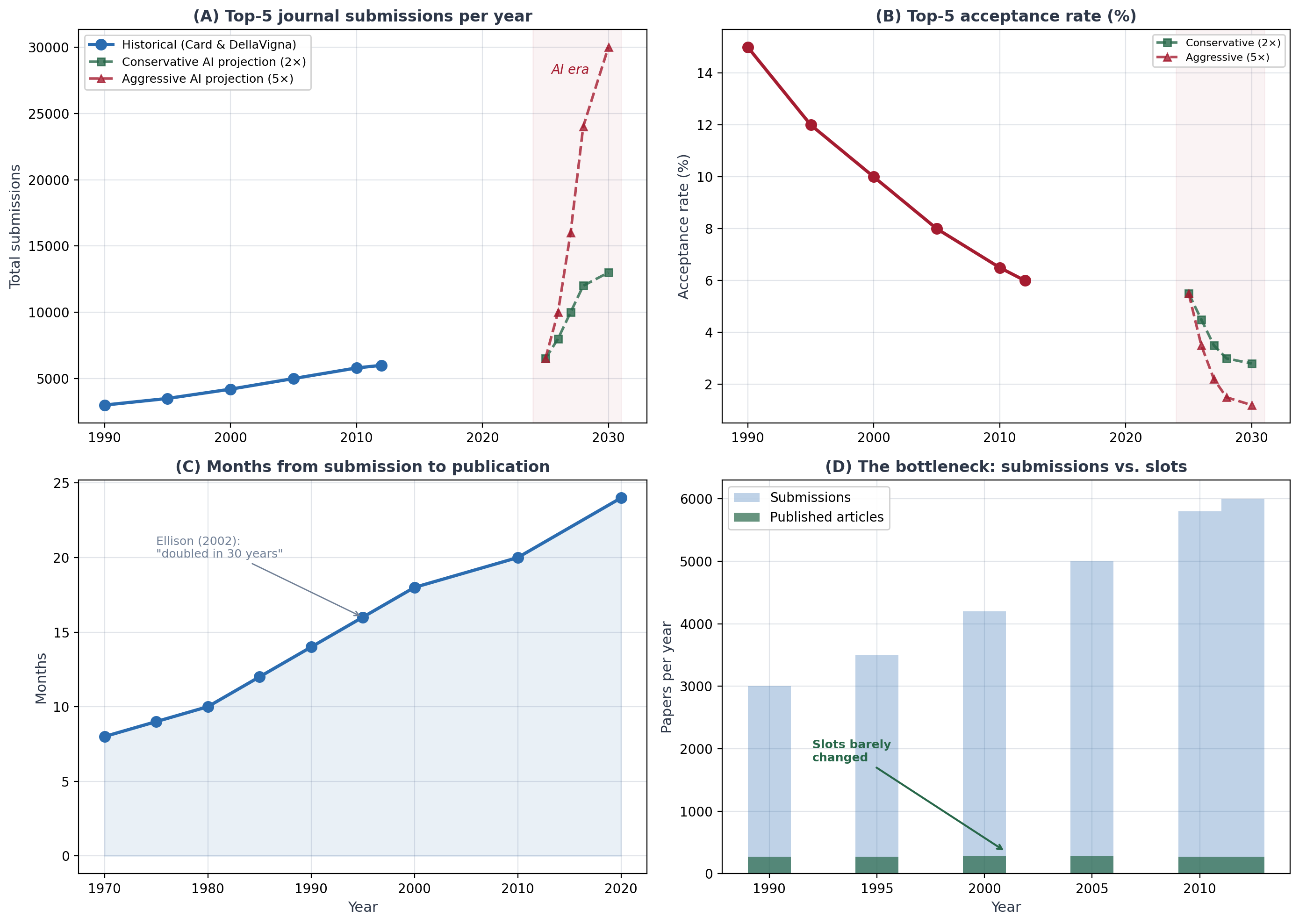
This is all driven by increased inflows, I. And in the stock-flow identity and Little’s Law, it cascades through the system. Increased pressure at every stage. And since we were already in a fairly durable and challenging equilibrium as it is due in part to our larger papers, longer time to writing them, and difficulty cracking top journals, only worsens the bottleneck.
Which means that AI doesn’t create a problem, but rather worsens an already existing problem. And if labor productivity is even modest, the bottleneck can literally break by increased refusals by referees which causes even more problems. All of this is coming from production while keeping evaluation the same. This has nothing yet to do with publication.
The desk rejection math is brutal
The only lever editors can pull quickly is desk rejection. Send more papers back without review. Here’s the arithmetic.
To keep the review queue stable when submissions multiply by some factor k, you need to increase desk rejection enough to hold the flow into review constant. The formula is simple: the new desk rejection rate equals one minus the quantity one minus the old rate divided by k.
From what I can gather based on the time I have to write this and the resources I have at my disposal, I am going to just assume that the typical field journal (e.g., Journal of Labor Economics) currently desk-rejects about half its submissions. Any number will work, but I’ll use that as my example for now. So assuming that that is roughly true, then here’s what happens next.
To keep the stock constant on referees, at 2x submissions, desk rejection has to rise from 50% to 75%. At 3x, from 50% to 83%. At 5x, from 50% to 90%. At 10x, to 95%.
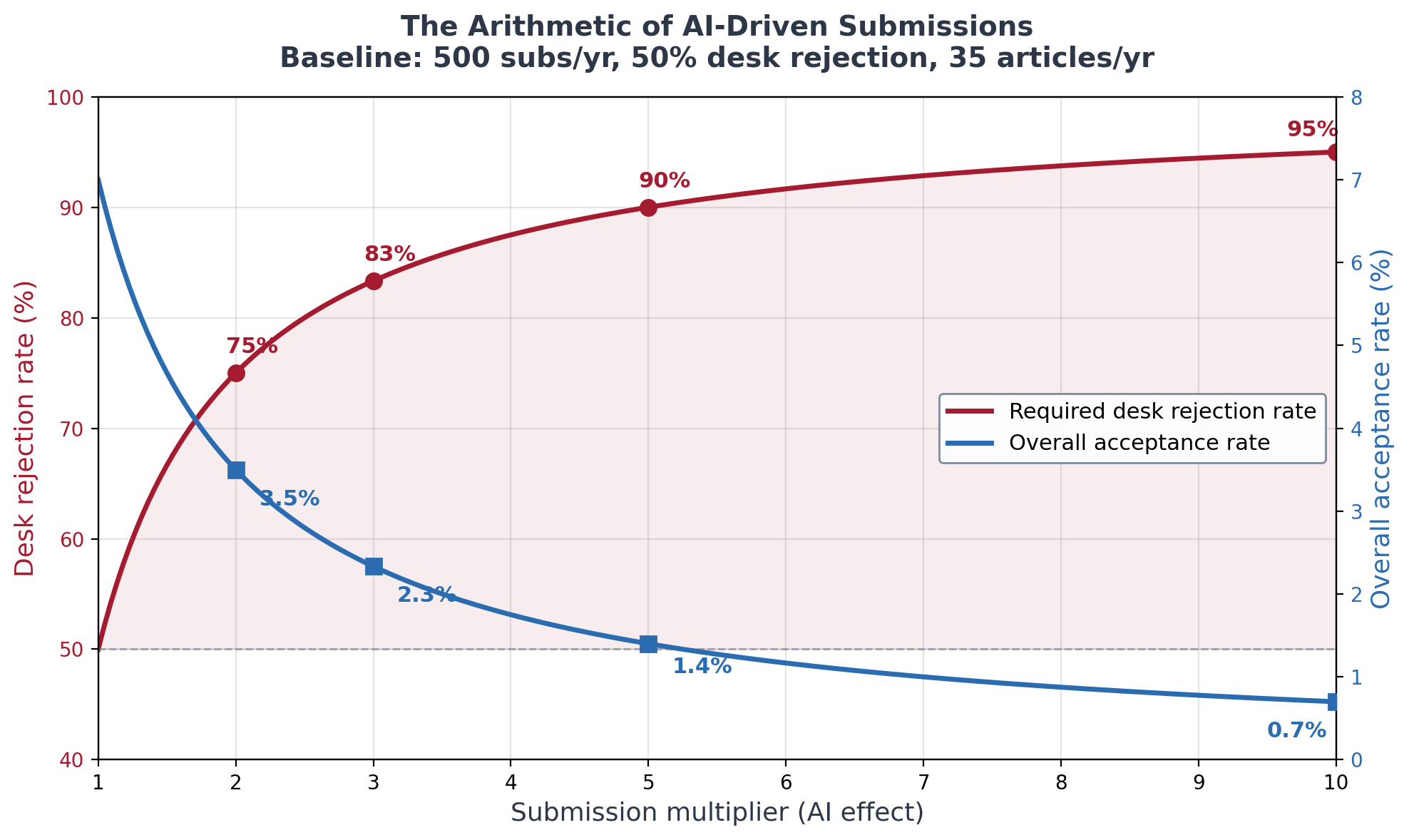
Thus a field journal currently getting about 10 submissions a week who with AI see submission grow three-fold now see 30 per week. The editor would need to desk-reject, therefore, around five out of every six papers which means they are triaging six papers per workday just at the desk stage, before any actual reading happens.
As I said in the earlier post, though, this is not straightforward. The heuristics editors have historically use to make such quick decisions are being weakened by AI, too. Why? Because the submissions are better. Field journals often publish papers with publicly available data, and as they are also causal in nature, following methodological formulas due to repeated refinement over time, there’s an abundance of them in the training data, and AI know show to write them well.
Some top field journals (I won’t name names) are as high as 90% difference-in-differences papers alone over the last decade. Diff-in-diff in particular follows a regular rhythm using frequently geographic level variation in policies, often publicly available data, presented event studies, and with these robust diff-in-diff estimators having tens of thousands of citations, are methodologically advanced too. And as those are recent, and given economists post working papers religiously, these two are in the training data.
Which means AI has more or less plotted the rhetoric of causal inference down to the letter. And thus the heuristics of desk rejecting those types of papers is gone. Editors don’t just look at papers that are performed poorly and rejected in a second. They are not looking at methodologically “non credible” papers and rejecting quickly. They are looking at higher quality papers across the board, making it much harder to desk reject.
Thus the quality-quantity composition at the desk has shifted immensely, and the noise to signal ratio collapsed. The AI-assisted papers will now be harder to desk-reject. It is not, in other words, merely that there are more of them — it is that there are more and better on a per submission basis. They’ll be better written, better formatted, with clean code and almost certainly longer with more appendices due to the ability to perform every single robustness check conceivable.
And so the signal that used to help editors triage quickly such as sloppy writing, missing tables, glaringly obvious reasoning errors will disappear. Every paper will look competent on the surface, and the long left tail of quality will disappear. It will no longer look like the normal distribution as the probability mass under the density will just be this massively thick left tail at minimum, and as the desk reject decision is off the left tail, it will not be easily discernible what to reject at all because, ironically, these are better manuscripts! Editors would be rejecting better manuscripts! Which defeats the entire purpose of the journal’s existence in the first place. It is very hard to justify a goal of rejecting more of better scientific manuscripts when the goal of science is to publish more of those, not fewer.
Which means that the editor will have to read more carefully to distinguish the ones with genuine contributions from the ones that are just well-polished nothing. But since AI most likely is in particular augmenting the production-side of workers with less skill, there’s actually no reason to reject more of them. If anything, they will want pass along more of them because under counterfactual without AI that is what they would be doing when they would have seen this manuscript!
You see how all this logic is just canceling out the outflow and thus the stock-flow identity is forcing the stock to rise? Forcing the manuscripts to rise under consideration? Forcing the manuscripts per referee to rise? And thus straining the bottleneck, potentially to extinction?
The extensive margin is the part nobody’s talking about
Most of my earlier analysis focused on the intensive margin — existing researchers producing more papers. A productive economist going from two manuscripts a year to six. But I think the extensive margin may be bigger, and it’s the part that really scares me.
Remember Conley and Onder’s numbers. 90% of PhDs barely publish. There is a massive population of people with graduate training, data access, research questions, and institutional affiliations who currently produce approximately zero papers per year. Not because they lack ideas. Because the execution cost was prohibitive. They teach four courses a semester. They don’t have RA budgets. They haven’t touched Stata since their dissertation. The fixed cost of setting up a research project — learning the latest estimator, cleaning the data, debugging the code, producing the tables — was simply too high relative to the time they had available.
AI eliminates that fixed cost. Adjuncts at teaching colleges. Policy researchers at think tanks. Government economists at federal agencies. Grad students who previously needed two years of coursework before they could produce anything. Researchers in developing countries without institutional support.
This isn’t speculative. A 2025 analysis in Science found that 36% of manuscripts submitted in the first half of 2024 already contained AI-generated text. Only 9% disclosed it. Also see this one.
Researchers using generative AI are publishing more papers is my point.
The extensive margin so to speak was already activating even before Claude Code, and it’s clearly Claude Code that is the most productivity enhancing technological shock as unlike traditional LLMs like ChatGPT, AI Agents don’t just talk — they primarily do things. And it is the “doing of things” that is the real transformation of worker’s production functions due to reduced time use with simultaneously better coding practices, fewer errors, better reasoning, and better writing, all of which leads to less time per manuscript.
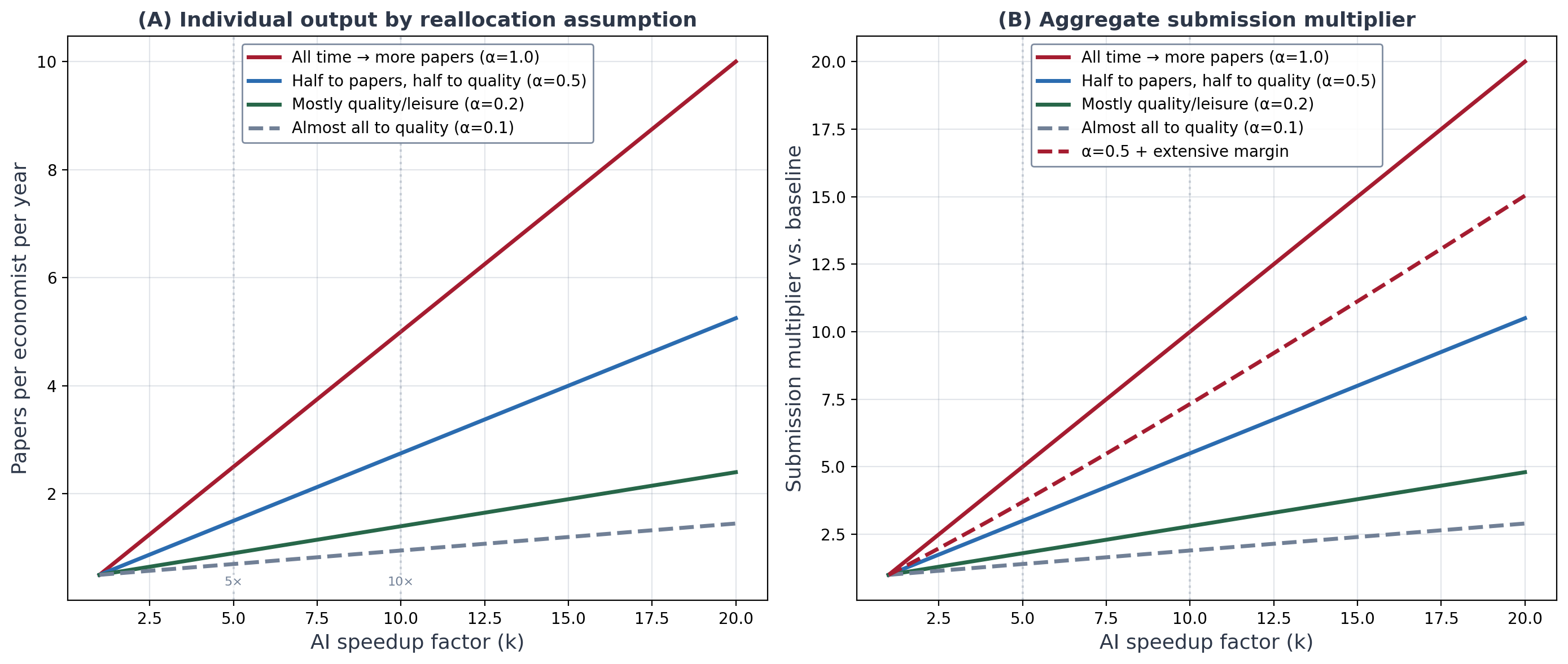
If even a fraction of the 80% of economists who currently produce almost nothing start submitting one paper a year, the aggregate effect dwarfs anything the intensive margin can do, but almost certainly the intensive margin will experience its own change in productivity. But just think about that Pareto principle for a minute — 80% of all PhD economists is a massive quantity of economists. Which is whether are really simple scenarios where this stacks up and fast — especially in light of changing labor markets in general.
Just to name two, we have federal cuts to overhead leading to smaller university budgets leading to fewer lines. And we have birth cohorts getting smaller each year after the Great Recession causing universities to get a double whammy by reducing enrollment cohorts, and thus reducing tuition revenue too. Thus at the extensive margin, given the desirability of faculty jobs, almost certainly a race ensues among younger cohorts, leading to even more strain on referees who are older.
The Enrollment Cliff and the Missing Babies: Who Wasn’t Born?

Today’s post is paywalled courtesy of coin flips. It’s a bit different than. normal, but it’s something I’ve been thinking about regarding declining fertility and higher education. Enjoy! And consider becoming a paying subscriber!Scott's Mixtape Substack is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
A modest proposal for editors
So, with that out of the way, here’s where I want to spend the rest of this post. Because I think the diagnosis from previous plus the stock-flow identity above is essentially right, I think it’s now vital to throw out ideas, if only to give ideas to editor-in-chiefs, co-editors, associate editors and editorial boards. Even if these ideas are rejected, they hopefully can be topics for consideration, and by me posting them, maybe defuse some of the awkwardness that people may feel about even bringing it up. So I’m glad to throw out some ideas.
What should editors actually do?
And I have four proposals, ranked by how quickly they could be implemented.
1. Decide on the journal’s goal
Before any prescription, editors need to have a conversation that they may not have been planning to have and may even have not wanted to have. What is the journal’s objective function? What is peer review actually for? Why should this journal exist? What is the cost to society if it does not exist. Such conversations are often grouped under a business school phrase called “the value proposition” and it refers to articulating clearly the economic value of the product or service itself. And so the journal must do that, and encourage its staff (and probably its constituents, which is the entire profession, but let’s just focus on staff since the transaction costs are lower to do it there, plus they are the ones managing the inflow and incurring the resource costs from peer review).
It is vital to have this conversation first, and be clear about the decided upon objective function, because all policy recommendations flow from it, and there are at least two different answers to it, and they are completely exclusive of the other.
The first answer is AI prohibition. It goes something like this.
AI-generated research is fundamentally unethical. It violates something about what scholarship means, even if the violation is hard to articulate precisely. It should be banned. It is based on stolen work.
You will find a variety of ethical and philosophically rooted claims around the AI prohibition viewpoint. You may even find the seemingly abandoned “labor theory of value” buried inside it since LLMs have been trained on economists’ and programmers’ own time intensive prior work, and thus often triggers claims that LLMs commit constant piracy.
Under the AI prohibition objective, the right policy is detection: build tools to identify AI-written manuscripts and reject them. And many economists feel this way. I am told the social media platform, Bluesky, consists of a high proportion of economists who feel strongly this way, and no doubt they are a passionate and articulate group of economists that are but the tip of the iceberg.
I want to say something that I think matters: those economists must be encouraged to speak up, and their position must be genuinely respected. Maybe that goes without saying, but many things that go without saying merit saying it to establish the norm anyway. I don’t mean feigning respect too. I don’t mean “being polite”. I mean respect, which is active listening, understanding, being patient, not interrupting, and interacting seriously with each person even and especially when one strongly disagrees with what’s being said. Economists as a lot are intelligent people driven by a desire to do right by their science, and if they believe AI in research is wrong, that belief deserves a real hearing.
The second answer is to recognize, though, that the purpose of peer review, and therefore the justification for every journal’s existence, is decidedly not to help anyone keep their job. The purpose of peer review is not to help economists get tenure. It is not to help them increase their incomes and wealth, get prizes, enhance their prestige. It is not to help them in a quest to put more lines on their vita.
We did not collectively invent peer review, and science itself, in order to build a journal system in order to employ workers. In fact, employing workers and satisfying their inner desires is irrelevant.
Peer review was not invented as some Keynesian experiment like building bridges to nowhere.
The entire purpose of peer review and journals is to propel science forward through innovation, accurate facts, and better theories about the real world. And in economists’ own models like Paul Romer’s endogenous growth theory, the recent Nobel work on creative destruction, the vast literature on the Industrial Revolution and what ended millennia of stagnation, it is a constant theme that ideas and science are what produced falling mortality, rising wealth, and broadly shared improvements in quality of life. The so-called hockey stick of human progress is a recent phenomenon, covering maybe 0.01% of our species’ timeline. It appears driven by science, literacy, numeracy, and public policy decisions that harness all three. Acemoglu and Johnson’s Power and Progress makes this case at book length.
These two objective functions produce completely different policies. If the goal is to block AI, you invest in detection. If the goal is to increase scientific innovation, and therefore to play our part in the project that bent the curve of human welfare, then you invest in evaluation infrastructure that can handle more science, faster, regardless of how it was produced.
I’ll state my position plainly. I believe the second should be our goal. I don’t think the goal is to identify AI-generated manuscripts. I think the goal is to increase the rate of scientific innovation through careful evaluation and propagation through policy and education. And the three proposals that follow are grounded in that objective function.
1. Adopt LLMs layers at the desk
If LLMs caused the flood, adopt LLMs to help sort it. This is the fastest lever and the easiest one to implement.
Using an LLM screening layer before human review could check whether the tables match the text will immediately flag problems. It could verify that code runs and reproduces the stated results. It could flag statistical red flags such as miscalculated p-values, robustness checks that appear comprehensive but test nothing meaningful, incorrectly calculated standard errors, identification strategies that don’t actually identify anything. It could even be trained on the editor’s tastes.
LLM screening doesn’t replace human judgment. Rather, LLLM screening gives the editor a triage “pre-desk report” so they can spend five minutes instead of thirty on quick desk-reject decision. At 30 submissions per week, that’s the difference between a manageable workload and drowning.
One can easily debate this policy, but I would just point out that the stock-flow identity is an accounting identity. Something must be done if we are to maintain our evaluation systems. So keep that in mind.
The irony is that the tool causing the problem is also the best tool for managing it. If an Claude Code can write a paper, then it can absolutely also critically read one and it can read thirty in the time it takes an editor to read one. So the question is whether editors are willing to use it, and my guess is that the ones who adopt early will survive this transition, and I think survival is a minimum prerequisite for peer review to persist. The ones who insist on reading every submission themselves will likely burn out and if it’s a journal policy, then replacement will be difficult, and you most likely invite negative selection at the top and throughout the editorial pool.
2. Require code repositories at submission
This is the highest-value, lowest-cost intervention, and I think it matters even more than LLM screening. We should be requiring every author to submit their code at submission, and to post their project on publicly available repos too. We are decades into a major empirical crisis around credibility, and the reasons to not require this always involve researchers wanting monopoly rights over their ideas. Which is fine, but once the paper is ready for submission, in order to salvage the system, we need the code so that we can verify its accuracy even before we send it out.
And Claude Code can audit code extremely well, when one is skilled enough to know how to do it, without even the data.
So if every submission must include a working code repository that reproduces all results from raw data, several things happen simultaneously. First, it raises the cost of submitting half-baked, fake papers that have not been verified by the human authors ahead of time. A code repo that actually runs requires real data and real computation, not just well-formatted LaTeX. Requiring this would improve the quality of science, speed it up, and since it uses LLMs for checking quality first, it will assist referees by signaling that major problems have already been checked. The referee Bayesian updates upon receiving her assignment knowing that it has already gone through a code audit, and thus the cognitive load of thinking about that particular form of hallucination is at least vanishingly small. And if the referee can literally see the code, they can also check for basic syntax mistakes themselves.
Some journals already require data and code deposits for accepted papers. The AER has done this for years. Journals will absolutely keep falling suit if they are not already. So this requirement also speeds up the entire publication process by getting authors into the habit of generating replicable code, and given the marginal cost of replication has also dropped to zero, it helps authors take seriously that they too are probably going to be targets by swarms of people looking to take down a manuscript.
My proposal is not to require replication. Rather it is to require it replicable source code at submission, as opposed to just acceptance. Move the replication package requirement from the end of the pipeline to the beginning and you probably automatically address some of the abuses of AI which is papers that have zero human touch and thus zero human verification anywhere.
The objection I anticipate is that this creates an extra burden on authors. But if you wrote the paper with Claude Code, the code repository already exists. And if you haven’t, then you are going to do it anyway. Better get it out of the way. The marginal cost of packaging it is small to approximately zero, particularly if you use Claude Code to help you. The only people for whom this is genuinely costly are the ones who don’t have working code, and those are exactly the submissions you want to screen out.
Raise fees — carefully
Current submission fees range from zero to $800 like some finance journals. Most field journals charge $100 to $300 depending on one’s membership to the community association the journal is associated with. These numbers are negligible.
And yet they are now too low.
A journal receiving 500 submissions per year at $150 each collects $150 each collects $75,000 which is barely enough to pay a part-time editorial assistant. At $500 per submission, that′s $250,000 which is enough to fund one or two additional associate editors. At 3x volume, the revenue triples even without raising prices. With both volume increases and modestly higher fees, journals could build the editorial capacity they need.
Fees are a Pigouvian tax on the externality each submission creates because every paper has a real resource cost in a system with peer review. That resource cost is referee time. Referee time has an opportunity cost, which is foregone scientific innovation. Thus to send a manuscript costs society not just the editor’s but also three to five referees’ their time, and the author does not pay those costs — particularly if they are performing automation.
But I want to be honest about the distributional concerns. A blanket increase to $500 falls hardest on junior faculty without grants, researchers at teaching institutions, scholars in lower-income countries. Any fee increase likely needs price discrimination such as student rates, LMIC waivers, reductions for active referees. ReStud already does some of this, with reduced fees for early-career researchers. Although this is a double-edged sword given it’s highly likely that younger cohorts will have less antipathy to using AI for their work, and thus may generate more of it (particularly given research finding AI having large gains to the least experienced workers), price discrimination can still help the journals decide how they want to go about this or if the uniform pricing model is best for them.
And even at 500, the expected value calculation still works. A single top−field publication is worth a tenure case, a 500, a $20,000 raise, a presently discounted lifetime of increased wealth. Five hundred dollars is noise against that payoff. So fees alone won’t solve this. But fees plus code repos plus LLM screening together create a friction gradient that’s proportional to paper quality and forces authors to bet on their best papers and not simply play a lottery and throw as many lines into the ocean as they can. Bad papers get caught by the code check. Marginal papers get caught by the LLM screen. Only papers that pass a MB-MC test will end up imposing resource costs on a human editor’s time, and those that do reach it, will be generating more revenue which editors can use to make long run adjustment planning.
The long run will sort itself out. The transition won’t.
Joshua Gans wrote a thoughtful response to Post 27, and I want to engage with it honestly. His argument, roughly: the equilibrium will adjust. Higher fees, new journals, new norms, better AI that improves quality not just quantity. The market will sort it out.

I agree with on all three. In the long run, the profession will adapt. New institutions will emerge. AI will get better at both producing and evaluating research. But of course, in the long run, we are also all dead.
It is the transition dynamics that are the problem. Neal and Rick’s prison analogy again is helpful. The US prison system did eventually adapt . It did so by building more prisons which cost upwards of $80 billion a year. The human cost during the adjustment was staggering and probably not particularly thought out given the prison boom selected on some groups more than others creating their own loops from labor market scarring and recidivism. The fact that a system reaches a new equilibrium doesn’t mean the transition was painless nor that the new equilibrium is the best one. It also does not imply that the invisible hand operates absent human intervention — the invisible hand happens via human intervention, rather.
My personal opinion is that editors don’t have the luxury of waiting for the long-run equilibrium. They’ve been getting more and longer submissions for a long time, and it’s hard to simultaneously hold the position that Claude Code will raise economists’ productivity and somehow not increase output. And if it increases output, it is impossible under this stock-flow identity for it not to increase manuscripts per editor and manuscripts per referees.
So to me, the question isn’t whether the market will sort it out eventually. It’s what you do right now, this spring, this summer, 2026, when the queue is already growing as part of longer trends, the tools continuing to improve, economists realizing en masse and quickly just how radically transformative AI agents can be, and the clocks ticking.
The binding constraint shifted
As I said in post 27, for most of the history of academic economics, the binding constraint on science was production. It was hard to do research. It took time, and it particularly took economists a long time for whatever the reason. This is evidenced by our low annual production compared to psychology or medicine. Our papers are longer, we typically don’t spread the contribution out over multiple papers but rather stick them into one paper, requiring entirely different forms of rhetoric and structure and strategies to deal with contradictions.
It is hard to clean data, particularly large surveys and administrative data. Both of these can take a tremendous amount of time and for very different reasons. The econometrics is constantly evolving and researchers are expected to use them. And it is hard for everyone to write clearly, and therefore altogether it is hard to produce the finished product that constitutes a journal submission. The entire institutional apparatus like PhD programs, research assistants, seminar culture, the slow pace of publishing, was designed around the assumption that producing good work was expensive.
And now, every day, that assumption is being relaxed. Production is getting cheap. That’s an empirically verifiable fact.
Claude Code 29: Can Claude Code Find Facts? And If So, Should I Believe Them?

Monday’s post was what I called Claude Code fan fiction — a supply-and-demand analysis of what happens to academic publishing when the cost of producing a manuscript collapses. It went viral, which I did not expect. This post is the companion piece, but it’s about something different. Something that’s been bothering me more.
The binding constraint is shifting to evaluation, which is to say it is shifting from production to figuring out which research is good, which paper is innovative.
And that’s a fundamentally different problem requiring shifts in institutional designs. The editorial system was designed for a world where production was expensive and evaluation was the bottleneck only at the very top. Now, in the new world, production is cheap and evaluation is relatively more expensive. Wherever outflows are constant, there is now a bottleneck — not just at the AER, but at the JHR, at JOLE, at Economic Inquiry, at every journal in the long tail.
The question isn’t whether we should expect AI to be used in research. That ship sailed. To say otherwise is to live in denial. The question is whether we design institutions that can handle what AI produces or whether we let the queue grow until the system breaks under its own weight.
I don’t think editors have much time to decide. So I submit this post to editors for their consideration, and anyone else interested.
These are questions worth discussing at all journals. There are some journals that prohibit the use of AI when reviewing papers which seems odd if authors are using AI already. I also wonder if In addition to raising fees you can limit the number of submissions an author can make in a year as well.
Many publishers saw a ~20% increase in submissions last year. Everyone expects the same to happen this year, perhaps more. Working out how to deal with the increase of AI-generated slop is keeping a lot of people awake at night within the academic publishing industry.
Your article focuses on genuine papers, produced by "good actors". There are also many bad actors out there (e.g. paper mills) that are looking to publish at scale to make quick cash.
Here are a couple of articles, published recently, that discuss this topic:
The emerging submission crisis in behavioral science
https://www.sciencedirect.com/science/article/pii/S2211949326000013
Ninety-seven ignored: A personal reflection on the hidden struggles of an academic editor
https://ese.arphahub.com/article/182020/
This quote from the second article sums up what many editors are experiencing:
"Managing approximately 20 manuscripts required sending dozens to over a hundred reviewer invitations per article, often yielding few or no responses and prolonging decision timelines. The relentless, voluntary nature of this work resulted in significant mental fatigue, intrusion into personal life, and eventual burnout, culminating in my resignation from both roles. This reflective account highlights the demanding, often invisible labor of editors and calls for greater empathy and support within the scholarly community."
Submission fees get discussed a lot by publishers. I expect more publishers to roll them out, although they will be wary of introducing barriers for LMIC authors.
This is alternative take that's worth considering:
https://scholarlykitchen.sspnet.org/2025/11/04/manuscript-submissions-are-up-thats-good-right/