


The last two weeks have been a real whirlwind. I presented at Harvard Medical School early last week, gave the keynote at Georgetown’s McCourt School of Public Policy faculty retreat last Thursday, spoke at the Harvard Kennedy School earlier this week, and yesterday I was a guest speaker in Alberto Abadie’s “Topics in Econometrics” class at MIT. Four talks, four different audiences. There were health oriented scientists, theologians, philosophers, political scientists and economists of a huge range, not to mention many faculty and many students. And roughly the same underlying material each time: what AI is doing to the possibilities of research practice of empirical research.
But I don’t want to use this post to recap the talks. I want to use it to write down what I’m learning from giving them, because the most interesting thing about doing this many of these in a row is that the audiences keep teaching me what they need to see, and what they need to see keeps changing my sense of what the demo is actually about.
A short detour: the paper I used at Kennedy
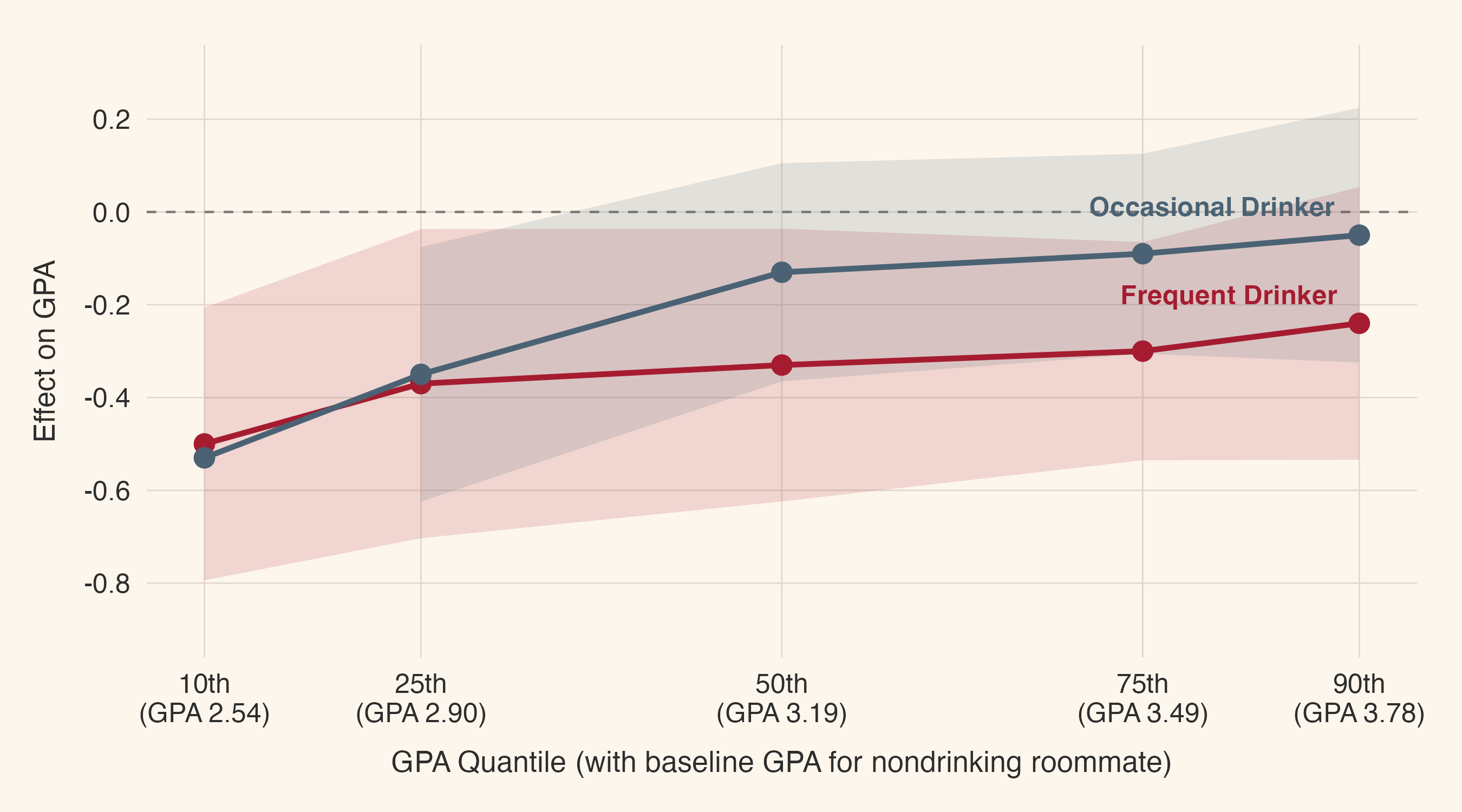
For the Kennedy School talk I built the demo around a paper by Michael Kremer and Dan Levy entitled “Peer Effects and Alcohol Use among College Students,” published in the Journal of Economic Perspectives in 2008. Let me first tell you about the paper before I tell you about the theatrical stunt that I used the paper for.
The setup in the paper is beautiful. A large Midwestern university ran a housing lottery that randomly assigned freshman roommates conditional on a few preferences. Some students arrived having reported on a survey, before college, that they drank in high school. Others reported they didn’t.
The finding is that male students who got randomly assigned a roommate who had drunk in high school lost roughly a quarter of a GPA point, which is about as much as a 50-point drop on the SAT. The effect was concentrated among students who were themselves already drinkers, and it was worst at the bottom of the GPA distribution which are obviously the students who could least afford such negative shocks.
And here is the part that lands hardest: the effect grew larger in the second year, even after the roommate had moved out. Whatever the mechanism was, it wasn’t noise or disruption, but rather something like a slow shaping of a young person’s preferences by the person they happened to be sleeping ten feet away from. The university chose who you lived with, and that choice rippled through the rest of your time there.
That is a wonderful paper to use for a public talk because the causal logic is clean enough to teach in five minutes and the human stakes are obvious to anyone who has ever lived in a dorm.
Except that I didn’t teach it. I didn’t say much at all about it.
The theatrical stunt
Here is what I actually did at Kennedy. I had not prepared slides. I showed people that the folder entitled “Kennedy” was actually empty. It was more or less meant to be like when a magician asks a volunteer to review a deck of cards and confirm that there is nothing fishy with it for the crowd so that the crowd could verify that there was nothing fishy with the deck too. Even better would’ve probably been to pick randomly on someone in the crowd and just ask them to give me a paper — any paper — and I use it instead.
I want to be clear about that because the whole point depended on it. I opened my laptop in front of the audience, pulled up Claude Code in a terminal, and gave it one prompt typed live, full of typos because I was talking and typing at the same time. I used the “- - dangerously-skip-permissions” modifier for claude from the CLI so that this would all run in the background as I went through my talk, which was again part of the suspense that I hoped would keep the median audience member engaged as they patiently waited for the outcome. Here was the prompt:
SO i am currently giving a talk on this paper at the kennedy school, and i need a couple of favors. number one i want you to use my /split-pdf and split the pdf into as many 4-page pdfs as you can and then write a summary per split fow hat you found what t is about, why we shoudl care who the audience etc. and then once you ahve all those markedown summaries, take another agent and summarize that into a single big throgouh markdown. Then, i want you to read my rhetor ic of decks essays and myaristotean essay about the rhteroci of beamer slides and then use my /beautiful_deck skill to make a beautiful deck in beamer that is aesthetically very pretty, and is intended for an audiecnc eof intelligent layperople without a background in alcoho policy and college peer effects. this deck will need to transatel all f ther regression tables into picture using R and .png and they must be accurate and very interesting. so that menas you’re going have to simulate the results that dan had and it acturally fit the real results. and make it 20 slides. make it pretty. have a story. lead with narrative, lead with facts. and make it cool
And then I hit enter, let it sit there a second so they could see it get fired up, and then I went to my talk. I did not return for another 15-30 minutes I think.
In the background, sub-agents spinning up. I had invoked my /split-pdf skill causing the Levy and Kremer (2008) PDF to be split into N pdfs of equal length (4-page pdfs). Markdown notes (for each of the N pdf splits) were written, with one additional markdown that upon completion swept through the N markdowns and wrote one big markdown summary. R scripts were drafted, then run, then debugged, all while I spoke. LaTeX beamer code was written, compiled, overfull/overfill/hbox/vbox errors were identified, fixed, then compiled again — a process that was repeated until there were no more compile errors, not even so-called small cosmetic ones. In my experience, they are never small, so I tolerate zero of them. A custom color palette was chosen. A frame-title style was designed. A visual audit pass ran over the figures looking for label collisions. And then 15-30 minutes later there was a “beautiful deck”. We opened it. It was not visually perfect, because I still have not perfected my skill to eliminate all the tikz and .png related visual errors, but still, it was pretty good for someone who was extracting coefficients and standard errors and confidence intervals and creating their own data visualization based on them.
Here is the deck for your perusal too.
Decks instead of papers
You have probably seen the other parlor trick with AI where someone in front of you has Claude Code write a fully autonomous program evaluation manuscript, but I think what I did is more impactful on a skeptical audience, and I want to now explain why I feel this way.
There is a lot of, let’s call, “Luddite” anxiety around the automation of cognitive tasks using AI Agents. Luddite in the historical sense — deep moral opposition to machines because of the job stealing nature of them. Insofar as AI can automate research, start to finish, then what is the role of a PhD? What is the purpose of the human? Do you even need a PhD to push the buttons? Are we overpaying, at that point, the button pushers?
So I think there is a temptation, when you’re trying to show people what AI can do for empirical work, to show it doing the thing they worry about most: writing a paper. Which I think is a danger because when they are morally opposed to that functionality, they will psychologically become engaged with fight, flight or freeze responses, none of which is desirable from my point of view. Plus, even if it did write autonomously the manuscript in front of them, the other issue where the quality of it cannot be assessed, not to mention the challenges of presenting it to a large crowd. You cannot, in other words, easily show them a manuscript, so who knows what is in there.
But you can show them a beautiful deck, and I don’t think decks trigger the Luddite repugnance the way manuscripts do. For one, we share decks already. Publishers send us sample decks (they don’t send us permission to plagiarize the textbook though both are cognitive output). They are very valuable, highly time intensive, and are frequently very bad. They take up a lot of a professors’ time, they are one of two modes (the other being the manuscript) describing the way researchers talk to one another. So immediately they are recognized as fair ground, or moreso at least, and they can be immediately verified. Plus, my prompt was very specific — notice how much direction I had over it.
This is why I felt that the Kennedy demo worked better than a version of “watch Claude write a paper”. It is not less ambitious to write a deck, but I think you have to at least somewhat acknowledge that recreating regression tables as simulated figures when you do not have the actual micro data and yet are told to simulate it using R from the published coefficients is, on a technical level, a wildly hard task, if not a seemingly impossible task, and arguably a more demanding one than writing a bunch of words. It is easier for the audience to receive, precisely because they are not being asked to render a verdict on a research artifact. Rather, they are being asked to watch a presentation come into existence in twenty minutes, and then watch a human — me — stand up and give it. And since the assignment was to convert regression coefficients and standard errors into something visual, they could also see that this was not some wooden thing. Rather it was requiring discretion and choices, and particularly, discretion and choices within the rhetoric of decks constraints. What, in other words, would work well for an audience? That was implicit in the assignment.
I think this is the right register for a lot of AI demos. Find the form of work where the AI is the medium and the human is the performer. Show that. Not “look what it wrote without me.” Show “look what we did together, in front of you, in real time.”
The technical surprise: nothing is ever lost
The other thing I am learning from this run of talks is more practical, and I owe it to a PhD student named Theo (Hey Theo!) who came up to me after the MIT class yesterday.
Dan Levy emailed me today and said he had spoken with Michael Kremer, the coauthor on the paper, and told him about the Kennedy demo and that Kremer was very intrigued. He wondered if he could see the deck and a recording of the seminar, and I happily said yes.
But Dan also asked if I could send him the prompt I’d typed. I sat down to write the email and realized, with some sinking feeling, that I had typed that prompt directly into the terminal using CLI during a live talk, two days earlier, and then closed the session. So presumably it was gone.
But then I remembered something the MIT PhD student told me yesterday. After my talk, Theo told me that it was necessarily mandatory to constantly keep progress logs because Claude already keeps them in JSON files on my laptop. When I started asking more about that, he smiled and said what I immediately knew myself — just ask Claude and he’ll tell me .
So I did. I asked Claude if he could look around the Kennedy folder and find the prompt, that I heard it was in some hidden .claude or ~/something thing, according to Theory.
And Theo was right. It was there. My entire session with Claude at Kennedy was sitting in a JSON file.
Which means that every session I have ever run with Claude Code is also sitting on my laptop. Every prompt I have ever typed. Every tool call Claude has ever made on my behalf. Every sub-agent it has spawned. Every file it has read or written. Every Bash command, every R script, every LaTeX compile, every error, every retry, every edit.
So when I had him review the Kennedy folder and the JSON file, I learned that the Kennedy session was 445 messages long and 3.7 megabytes of structured text. My original prompt was the very first line, typos and all, faithfully preserved.
I was able to send Dan the verbatim original. I was also able to send him the entire working folder, which you can see here, with the source paper, Claude’s reading notes, the design document it wrote before any code, the seven R scripts that produced the figures, the LaTeX source, and the full session transcript. The whole thing. Reproducible. Auditable. Available to him and Michael and any AI agent they want to point at it.
This matters more than it sounds like. One of the quiet anxieties about AI in research is that the work happens in a black box, that if I ask the model to do something and it does it, and I have a result, that does not therefore mean that I have a record of how the result was produced.
But that is not actually true. The record exists. It is sitting on my machine. I just have to know where to look, and that nobody had told me, and now I am telling you. The path on macOS, in case you want to look at your own:
~/.claude/projects/<encoded-working-directory>/<session-id>.jsonlOpen one. It is a startling thing to read your own session back from the outside. You see the agent thinking, the sub-agents reporting back, the dead-ends, the corrections, the moment a figure was finally rendered correctly.
You might even be able to detect things like whether the agent was p-hacking because of this diary it kept.
It is the closest thing I have ever seen to a flight recorder for thought.
What I am learning
Four talks, two weeks, four different audiences. What I keep noticing, across all of them, is that the version of the demo that lands is the version where the AI is doing something that looks impossible right up until the moment it works. Writing a paper does not look impossible to a research audience because they have read enough mediocre papers to know that the bar is low. And it takes more than a couple of minutes to evaluate the quality of a paper, and it is quite easy to dismiss one if you are significantly biased against AI automated research anyway. So I don’t recommend that when you are trying to show people about AI agents. I think, instead, consider the deck — the beautiful deck.
Building a beautiful, original, narratively-arced presentation about a stranger’s paper, with simulated figures faithful to the original tables, in the twenty minutes before the talk starts looks and feels like an impossible magic trick. They are going to think the dice are loaded or that you have an ace up your sleeve because that is the response to magic tricks. Why? Because when a magic trick is done well, your brain cannot process it, and therefore you reach for many explanations.
Well, that assumes that the trick landed. And that is why you do this kind of “beautiful deck” demo — because it, unlike an automated paper, will land. It lands because they can from their seats see the success or lack thereof. And when it is done on a famous published study, then they also can immediately verify its accuracy or not.
It is the kind of task where the audience leans forward not because they are skeptical but because they genuinely cannot imagine how the next step will happen, and then it happens.
So that is the demo I am going to keep running. Not “the AI wrote a paper.” Rather, the “watch this thing come into existence in front of you, and then watch me give the talk it just made.” The AI is the medium. I am the rhetor. The work is shared. And, as it turns out, every single keystroke is preserved.
I thought the punch line was going to be that the paper didn't exist.
yesss! the history is great! with some organizing effort I have exploited this to build a "Claude HUD" that has project-level chat organization with quicklaunch and session history/restore, among other features: https://www.benjaminbdaniels.com/ClaudeHUD/