

Closing my tabs

It’s that time of week again where I close the tabs in my browser. Here you go.
Music and Media
Someone required kids to go on a camping trip and not bring their phones and they had fun. This is a dog bites man story if I’ve ever read one. Also, the author called this an experiment but it’s actually an anecdote as an experiment would require sending kids camping with a phone. You also need to probably do it like 500 times. So, it is both not an experiment, and nevertheless I don’t doubt that they had fun on their camping trips, and I also using introspection 100% believe that their camping trip would’ve been spoiled had they brought their phones. Below I have a link where a team of scientists predicted treatment effects without access to the RCT, so maybe I’m a large language model and don’t need an experiment either.
I’ve switched back over to listening to Apple Music again since I got this Apple Vision Pro. Even though you can get ripped off version of Spotify on it, because you can’t organize your Home Screen, it’s on the last “page”, whereas Apple Music is on the front page. So I have been listening to a station Apple makes for me called Scott Cunningham’s station and it’s been a delight. Yesterday Alice In Chains came on and it was like someone sprayed me in the face with a firehose of nostalgia. Holds up.
Did you know that players only love you when they’re playing? Also, women will come and they will go. But the good news is that when the rain washed you clean, you’ll know. Don’t believe me? Listen to Lissie’s cover of Stevie Nicks and prove me wrong.
Remember the Blair Witch Project? Argh. It hurts to even say this, but in 1999, for months I was awaiting its release, following every detail I could find on the Internet about it. It was a different time then — if it was on the internet, it was true. I’d never heard of “misinformation” except for propaganda, and the Blair Witch Project was best I could tell a true story. A group went into the woods, and for reasons that made no sense to me or anyone else, filmed themselves the entire time. They were lost and the footage was found and it was supposedly pretty terrifying. Why? Because I told you — it was true. Well, I doubt I’m spoiling anything 25 years later, but it wasn’t true. Of course it wasn’t true. But man what a rush it was thinking it was true. That is, until the day before and I learned it was not true from a bartender in Knoxville, Tennessee that somehow had a bootleg copy of the movie, gave it to me, and told me as he gave it to me “it’s not true, though”. He might as well have punched me in the face right then and there. Anyway, it’s the 25 year anniversary. The movie was made on like a $40,000 budget and grossed $250 million.
On that note, I had the same experience with Slender Man. Which is even more fascinating. You can watch Slender Man on Youtube channel “Marble Hornets” which has some pretty slick practical effects horror “scare scenes” that I don’t even like thinking about they scared the crap out of me so badly. And I was an adult then! A professor even! Here’s a history of Slender Man, which started out as a contest on Something Awful, and grew from a community of users adding to it until it became, well, terrifying to this guy.
Speaking of music and media, The Economist reports that 75% of Taylor Swift’s 1.4 billion dollar wealth came in the last five years. The “Taylor’s Versions” was a huge success, as was the Eras tour. I’ve decided to rewrite all my old articles and go on a speaking tour to try and do the same.
Family and Self Help
A new documentary called “Daughters” is streaming on Netflix. It’s about the Date with Dad program which allows children to be brought to their parents in prisons for a party, dancing, refreshments and opportunities to take photos and talk. NYT reviews it. I’m posting the gift link to see if all my readers without a NYT subscription can read it even though it’ll be used more than once. Not sure if it works that way, but let’s see. I’ve attended a thing like this before, though. I attended a prison where the family of prisoners were allowed to come and was nearly brought to tears. It was a huge party for prisoners in a particular program, and they had stand up with several prisoners doing stand up comedy. I couldn’t how legitimately hilarious they were. I remember this one guy saying “They say that the first thing you’re supposed to do when you get to prison is go up to the toughest guy you can find and punch him. I cannot imagine worse advice.” I was like “thank you, because I thought I was going to have to do that if I was ever falsely imprisoned, and now I’m going to do as I anticipated that being my last moment alive on this earth.”
Robert Putnam wrote a famous book in 2020 called Bowling Alone: The Collapse and Revival of American Community. A lesser known but somewhat similar article was written 3 years earlier entitled “Our Vanishing ‘Third Places’” by Roy Oldenburg. He opens the article like this:
Most residential areas built since World War II have been designed to protect people from community rather than connect them to it. Virtually all means of meeting and getting to know one’s neighbors have been eliminated. An electronically operated garage door out front and a privacy fence out back afford near total protection from those who, in former days, would have been neighbors.So what are “third places”? Think of your house as one place, your job as a second place. Third places are places other than your home and your job where community flourishes. For many today, they probably try to make social media their third place, and maybe it is, but I suspect the platforms are not designed to be third places so much as they are designed for you to constantly open the app and scroll and leave small comments. Third places, he writes are:
Third places are nothing more than informal public gathering places. The phrase “third places” derives from considering our homes to be the “first” places in our lives, and our work places the “second.”
Americans long enjoyed third places in the form of the inns and ordinaries of colonial society, then as the saloons and general stores springing up with west- ward expansion. Colonial Taverns. Later came the candy stores, soda fountains, coffee shops, diners, etc. which, along
Just some of the regulars.Speaking of colonial taverns, an interesting new article in the Journal of Development Economics on beer and water came by eyeballs this week which seems like it fits. The results of it are so similar to things I’ve thought for 20 years, so I totally believe it and haven’t read it. Again, as a human LLM, I don’t need to run the experiment (see below for this joke having more context). I literally have thought this now for almost 20 years because when I proposed to our old church we should switch from grape juice to alcoholic wine in communion, I had this whole speech I gave about the history of alcohol and I went on a huge rabbit trail about how water used to be really undrinkable, but that alcohol was safer, and that I suspected that led to the teetotaler movement as it likely led to extreme amounts of drunkenness and alcoholism, which helped fuel the Methodist church’s decision to switch from alcohol in communion to grape juice when a Methodist deacon named “Welch” (not kidding) adapted pasteurization to force the grapes not to ferment into alcohol. Which I said proved that it was impossible that the church has historically used grape juice because the technology didn’t exist and that you’d need glass and so on and they just said fine we’ll do it go away and don’t come here again. You can read a little about it here.
Thomas Welch was fascinated by Louis Pasteur and in 1869, Welch invented a method of pasteurizing grape juice so that fermentation was stopped, and the drink was non-alcoholic. He persuaded local churches to adopt this non-alcoholic wine for communion services, calling it “Dr. Welch’s Unfermented Wine.”Anyway that’s not what I’m trying to share with you! The article is called “When beer is safer than water: Beer availability and mortality from waterborne illnesses” by Francisca M. Antman and James M. Flynn in the 2024 Journal of Development Economics. Here’s the abstract too.

I still wonder if Louis Pasteur’s invention of pasteurization led, ironically, to the 18th amendment which prohibited alcohol, which helped give the Mafioso a stranglehold on organized crime in America. I’m going text Zach Ward after this and see what he thinks. I fully expect him to reply like he always does and say “Scott, I really need to go.”
Expert reveals the 5 “marriage gasps” that mean a marriage is over. By which I think it means either qualitative evidence backs this, hot takes or a logit regression with a small sample. Regardless, it’s “constant fighting that doesn’t let up”, “having almost no common ground anymore”, “boredom”, “emotional distance”, “a change in geography”. Obviously, no one flips a coin on those things, so those are all endogenous.
Saying “You Constantly” is according to Psychology Today also a killer of loving relationships. It’s technically not true which is worth pointing out.
Artificial Intelligence and other science
Purdue University Northwest is offering an applied AI masters degree. You can read about it here. UT Austin already has something like that now. It’s a 7-month program. Hard to believe that what you can learn in 7 months is going to really prepare you for doing work in AI, but there you go.
A working paper at Harvard Business School’s website entitled “AI Companions Reduce Loneliness” finds, you guessed it, exactly what the title says. They study “AI Companions”, and conclude that AI companions alleviate loneliness somewhere on par with having conversations with an actual person, but more than activities like watching Youtube. Plus, they underestimate the degree to which AI companions will do that ex ante.
Scientists find humans age dramatically in two bursts — age 44 and then age 60. They looked at thousands of molecules in people aged 25 5o 75 and detected major waves at 44 and 60 which they suggest (speculatively) could be why certain maladies start to happen at certain ages. As a 48 year old, I am going to say I bet this is why I make a lot of noises when I stand up off the couch now.
Econometric issues with a small number of clusters
Ever wonder about the differences between having a small number of “clusters” versus a small number of “treatments”? That has always been something that I think people speak about almost as synonyms, but they’re not, even though I think they some things in common, namely the issues they bring up with calculating standard errors. I haven’t yet found a review article that walks through the issues of having small number of clusters versus small numbers of treatments, but I thought I’d put up some classics and newer ones on the topic for those that want to dig into it. Keep this in mind — you often can get into having small clusters even with individual level data if the level of treatment is at some aggregate level and you only have a few of those aggregate levels.
As a set up, think about Card and Krueger’s classic minimum wage study which had 410 fast food restaurants in Pennsylvania and New Jersey, but the treatment was at the state level — if the errors are correlated within the state, then you have two “clusters”. It isn’t that you’re required to say that the error structure must be correlated within states; it’s that it is very common for researchers these days to be agnostic and say “well, who knows, so I’m just going to do something that allows it for these invisible fast food restaurant employment errors I’ve never seen before to be arbitrarily correlated with each other because why not?” It’s part of the larger trends, I think, in applied work where we are less and less willing to make definitive statements about what things we cannot see are and are not, and instead prefer estimators and procedures that work when it can be anything. So start here with Jeff Wooldridge’s 2003 AEA P&P on it entitled “Cluster-Sample Methods in Applied Econometrics”.
Sadly, every time you are unwilling to say ex ante what the error structure is, then a diff-in-diff paper loses its wings as they say. In a classic, Bertrand, Duflo and Mullainthan (2004) discusses this problem within diff-in-diff and suggests three fixes. One is the bootstrap, one is something else, and one is “regress y post##treat, vce(cluster state)”. People tend to use the third because Stata.
There’s a huge number of these “small cluster” papers that went into Review of Economics and Statistics. Actually, I take that back. I think there’s four. <Don’t forget to ask Cosmos for a joke about how ReStat has a small number of papers about the econometric problems created by a small number of clusters and then ask Claude to rewrite the joke and make it funnier>. Anyway, Donald and Lang (2007) is one of the first in that run and like Bertrand, Duflo and Mullainthan (2004), they take aim at difference-in-differences.
Cameron, Gelbach and Miller (2008) on the small number of clusters and their solution — the “wild t bootstrap” (great name). The issue is that the asymptotic theory assumes clusters go to infinity, but in finite samples, what happens when you have a quite few less than infinity? Say you have five? This paper is a classic and notes that with from 5 to 30 clusters, your standard standard error formulas will give you standard errors that are too small and you’ll have false positives with hypothesis tests. So they suggest the “wild t bootstrap”. Man I just love saying that.
But what if you have “small” number of “large” clusters? How does the wild t bootstrap perform there? Don’t worry! Canay, Santos and Shaikh (2021) also have an Restat on this, but I haven’t read this yet one yet.
Then there are the “multi-way clustering” but I’m not going to get into that here. But you can! Here’s Cameron, Gelbach and Miller (2012). In the meantime, if you’re wanting to really dive into all these issues, there’s a really great Journal of Human Resources article in a great 2015 issue of the JHR that was devoted to causal inference in general by Cameron and Miller called “A Practitioner’s Guide to Cluster-Robust Inference”.
Econometric issues with small number of policy changes
And if you’re also wanting to know what to do when you have difference-in-differences, and plenty of clusters (i.e., you have 50 states) but unfortunately you only have a few policy changes or treatments. Well a small number of policy changes and a small number of clusters isn’t the same thing. Conley and Taber (2011) looks at the latter in, yep you guessed it, difference-in-differences.
But Buchmueller, Dinardo and Valetta (2011), use randomization inference.
If you didn’t know this, and many young people may not, John Dinardo was a David Card student at Princeton in the early 1980s and he passed away in 2017 after a fight with cancer. A conference was held in his honor in Ann Arbor in 2018 (he was at his death a professor at Michigan) and papers presented there were collected and published in an issue of JOLE. David Card, David Lee and Thomas Lemieux have the opening article about it here.
Randomization inference has been what has been traditionally done with the synthetic control estimator (see Abadie, Diamond and Hainmueller 2010), but
Victor Chernozhukov, Kasper Wu ̈thrich and Yinchu Zhu write about an alternative to randomization inference using conformal inference. This will get you confidence intervals unlike randomization inference which only gets you an exact p-value under Fisher’s sharp null. They looked at Manisha and my gonorrhea result in the above Rhode Island sex work paper using this procedure and write:
"Following Cunningham and Shah (2018), we exploit the unantici- pated decriminalization of indoor prostitution in Rhode Island in 2003. We find that decriminalizing indoor prostitution significantly decreased the incidence of female gonorrhea." - Victor et. al.Augmented synthetic control by Ben-Michael, Feller and Rothstein (2021) in an issue of JASA devoted to synthetic control, which was also where Victor’s paper with Kasper and Yinchu was published (as was the Athey, et al. matrix completion paper) presented a method for synthetic control when you have poor balance. I love this paper for a lot of reasons, one being that there is a solution to the common situation when synthetic control doesn’t have a great fit, and recall that the convex hull is crucial to the bias of synth. They use an outcome regression model, though, based on Abadie and Imbens (2011) paper in Journal of Business and Statistics bias adjustment paper, which is a paper I love. Anyway, you can implement Victor, Paper and Yinchu’s conformal inference procedure in the R package for augmented synthetic control if you’re wanting to do it. You can also use the jackknife. Both will get you confidence intervals on the estimated treatment effect.
And that is all I’m going to say about inference with small number of clusters and inference with small number of treatments in diff-in-diff and synthetic control estimators. Actually, correction — I’m going to have to say it all over again in the revision of the Mixtape. But that’s all I’m going to say this morning as I’m only supposed to be closing tabs for this substack, not opening new ones and then closing them which is what I just did.
But I will mention that as long as we are open to being completely agnostic about the error structure in clustered data, then maybe that agnosticism has been a more general phenomena. Here, for instance, is Heckman, Urzu and Vytlacil in a 2006 Restat talking about “essential heterogeneity” which one could say is also about agnosticism, but about the treatment effect values. Remember, it is that same kind of agnosticism about heterogenous treatments effects that struck a blow at difference-in-differences estimators, just not on the inference part. But you just wait… This story isn’t over yet.
More Economics and Econometrics
Andrew Lee is an economist at the FTC. Yesterday I got to thinking of his amazing job market paper from 2021. Check out what happened. The Constitution requires that a defendant have counsel provided to them if they cannot afford it. But the Constitution does not say how the government will finance it, nor what compensation scheme it will use to pay the defense attorney. Some places have public defenders, some use a wheel of private attorneys that are paid flat fees. Sometimes the wheel gets paid hourly. On the one hand, what does it matter? On the other hand, isn’t there a field called microeconomics that says incentives matter? Well Andrew found this amazing opportunity to study whether changing how attorneys are paid affects their labor supply along numerous dimensions that affect their clients. He writes “in 2017, six counties were mandated to pay counsel a flat fee per case disposed instead of an hourly rate while other counties continued to pay assigned counsel an hourly rate.” So that’s the two compensation schemes:
Government will pay indigent defense attorneys per hour of their time on the case
Government will pay indigent defense attorneys a flat fee per case
What happens to worker labor supply if there are positive marginal costs defending a client? If you’re paid by the hour, then you’ll work on the case so long as the hourly wage is higher than marginal cost. If you’re paid a flat fee, you’ll work up to some minimum number of hours, which you could just call the reservoir level. You can show that the optimal number of hours on the first is weakly more than than the latter. Andrew writes this beautiful paper using diff-in-diff and finds that changing to the flat fee basis led to:
defendants being 11% more likely to be convicted
defendants being 37% more likely to be incarcerated
lawyers spending 11% fewer hours on indigent cases
lawyers disposing of cases 25% sooner on average
lawyers 36% more likely to dispose a case on the same day as their first meeting with the defendant
It’s such a fascinating paper because it suggests that compensation schemes for indigent defense are directly relevant to the Sixth Amendment of the Constitution. I love this paper. I think about it every few months and wish it was in the AER so everyone could read it — in economics, but especially outside of economics. It seems incredibly important. Read more about it here: “Flat Fee Compensation, Lawyer Incentives, and Case Outcomes in Indigent Criminal Defense” by Andrew J. Lee.

Janet Currie and W. Bentley MacLeod have a 2020 article in Econometrica entitled “Understanding Doctor Decision Making: The Case of Depression Treatment”. It has careful analysis of patient claims data and shows that among skilled doctors, using a broader portfolio of drugs predicts better patient outcomes, except in those cases when the doctors’ decision violate “loose professional guidelines”, interestingly. And then the authors include a behavioral model that examines the tradeoffs between “experimentaiton” and “exploitation”. The model predicts and the results show strong returns to skill leading to greater diversity in drug choice and better matching of drugs to patients, holding constant baseline physician beliefs. Seems like an important paper to me.
I was for some reason apparently looking up things about the history of selection bias, trying to figure out just when and where it shows up. I think I was looking up stuff about early Don Rubin articles and then was looking up things about Jim Heckman’s dissertation in the early 1970s and Orley’s papers probably. Anyway, here’s an old working paper by Art Goldberger on selection bias when evaluating treatment effects from 1972. I haven’t finished reading it, but there are interesting issues about selection on observables in it. Also, Art’s abstract has two paragraphs. Just noticed that. I refuse to start a new research agenda on the history of the abstract in economics. I refuse to do it. Please all that is good in the world, please don’t allow it to happen. I might end up doing it.
Here’s Don Rubin’s 1977 classic article on selection to treatment “on the basis of a covariate”. He cites two of Goldberger’s 1972 working papers (one of them is the one I just linked to). Rubin would build on this again in his also classic article on the propensity score with his student, Paul Rosenbaum, in 1983.
Speaking of the propensity score, it’ll in a few months probably pass 40,000 cites. I think it is the second most cited paper at Biometrika, but I can't find where I read that, and I should know what’s number one but don’t. If you know either of those, post it in the comments, would you? I asked Rubin when did he notice that it was starting to have such an impact. He told me it was when he’d heard it being mentioned in expert testimony in legal cases. I’m interviewing him this year, so I’ll ask again just to make sure I got that right.

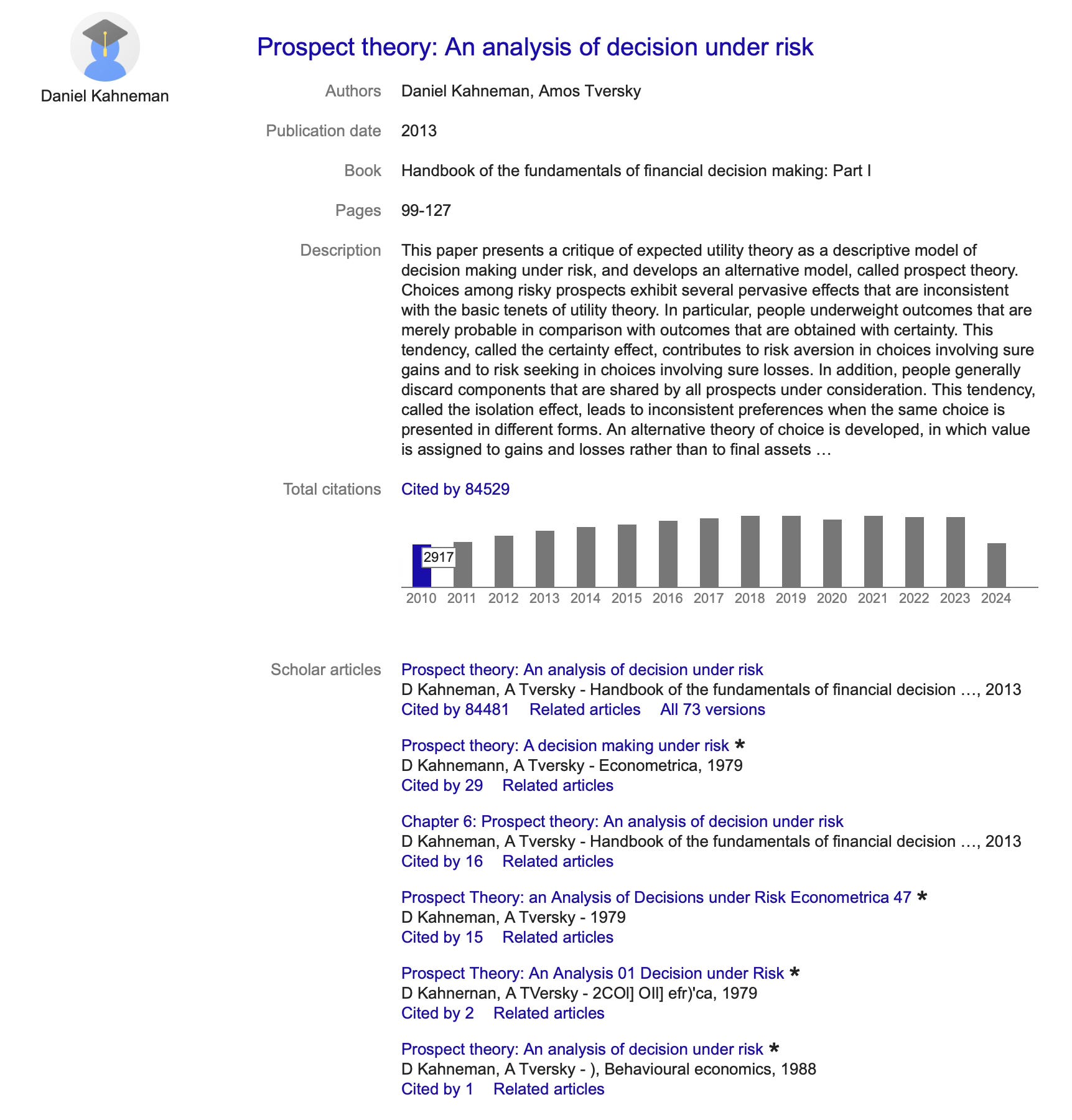
40k cites for a single paper, especially one published in 1983, is huge. Here, though, is Daniel Kahneman and Amos Tversky’s prospect theory publication was published in 1979 in Econometrica with almost 85,000 cites. But when was it published? Well according to google scholar’s screwed up algorithm, it was published in 2013, which I’m pretty sure is not correct as it has almost 3,000 cites in 2010. I think it’s the 1979 Econometrica which according to Google Scholar only got 29 cites. This is kind of frustrating, but if you click through you’ll find their citing the Econometrica, plus it’s the second one in that “all 73 versions” and that 2013 handbook chapter is apparently just repackaging it. Anyway, who cares. I care. I have a mental problem.
Here is Orley Ashenfelter’s vita which I guess I had open.
Here’s the webpage for the Dehejia and Wahba data for their 1999 and 2002 update to LaLonde’s 1986 article, which you can also find on there. I think it’s not controversial to say this, but Dehejia and Wahba making those data available has been a huge part of the elevation of not just their paper, but I bet LaLonde’s own original paper, in the larger public consciousness as it’s been used repeatedly for replication purposes and extensions. But how can it not be controversial if I literally cannot support with any data? Well, I think the definition of controversial probably requires people first care about the statement, and I doubt more than 5 people could possibly have an opinion about that.
Alex Bartik has been in the news lately because he’s coauthor on a big RCT that gave out, no strings attached, $1000 month for several years to poor families. His father is Tim Bartik who is often credited with the shift-share instrument because of his careful exposition in an appendix. But you know who will probably go down as the most famous Bartik of them all? Alex’s grandmother and Tim’s mother, Jean Bartik who was the first computer. No not that kind of computer. Jean Bartik was one of the original programmers on the ENIAC. Here she is standing by it.

Alex and coauthors did that RCT which I mentioned last week. It was funded in large part by OpenAI of ChatGPT fame. And last week I couldn’t remember where I’d read about this paper where a team of scientists trained a transformer model that ultimately was able to accurate predict treatment effects without an RCT. But thankfully, someone who read the substack sent it to me allowing me to open it in my browser and now closing it. Seriously, this description.
The model was front-loaded with de-identified data on millions of patients gleaned from health care claims information submitted by employers, health plans and hospitals – a foundation model strategy similar to that of generative AI tools like ChatGPT.
By pre-training the model on a huge cache of general data, researchers could then fine-tune the model with information concerning specific health conditions and treatments – in this case, focusing on stroke risk – to estimate the causal effect of each therapy and determine which therapy would work best based on individual patient characteristics.
The team from The Ohio State University reported today (May 1, 2024) in the journal Patterns that their model outperformed seven existing models and came up with the same treatment recommendations as four randomized clinical trials.
“No existing algorithm can do this work,” said senior author Ping Zhang, associate professor of computer science and engineering and biomedical informatics at Ohio State. “Quantitatively, our method increased performance by 7% to 8% over other methods. And the comparison showed other methods could infer similar results, but they can’t produce a result exactly like a randomized clinical trial. Our method can.”Well, what’s next when an LLM can perform an RCT without an RCT? Maybe it’ll know the correct error structure so we don’t have to be agnostic about it and get correct standard errors and not just the most conservative ones possible?
Psychedelic therapy
And now for a long article about the last week’s news in psychedelic therapy involving the FDA’s denial of MAPS/Lykos request for new drug application based on several RCTs and other data. This came to a shock to many, but I’m going to give as much background and details as I can, and many may not have the interest so I’ll put it behind the paywall.
But consider supporting the substack! You get the access to the full archive of around 200-300 articles (can’t remember) on causal inference, a ton of which related to difference-in-differences (here and here), the Mixtape mailbag (here) and coming soon, Mixtape University. But in the meantime, enjoy the free content too!
