


Today’s post is going to be very simple. All I’m going to do is show you average treatment effects by treatment status in three ways:
For an entire country of 1 million people who live in 10 states
County level averages which are then again averaged
State level averages which are then averaged
This is not a post saying which of these is “correct”. This is a post saying that they aren’t the same thing, and then providing an interpretation. But the larger point is simple: state level data corresponds to a different target parameter than county level data.
But first, let’s flip a coin to determine the paywalling. Heads it’s behind the paywall. Tails it’s free. Best out of 20.
<He flips a coin 20 times>
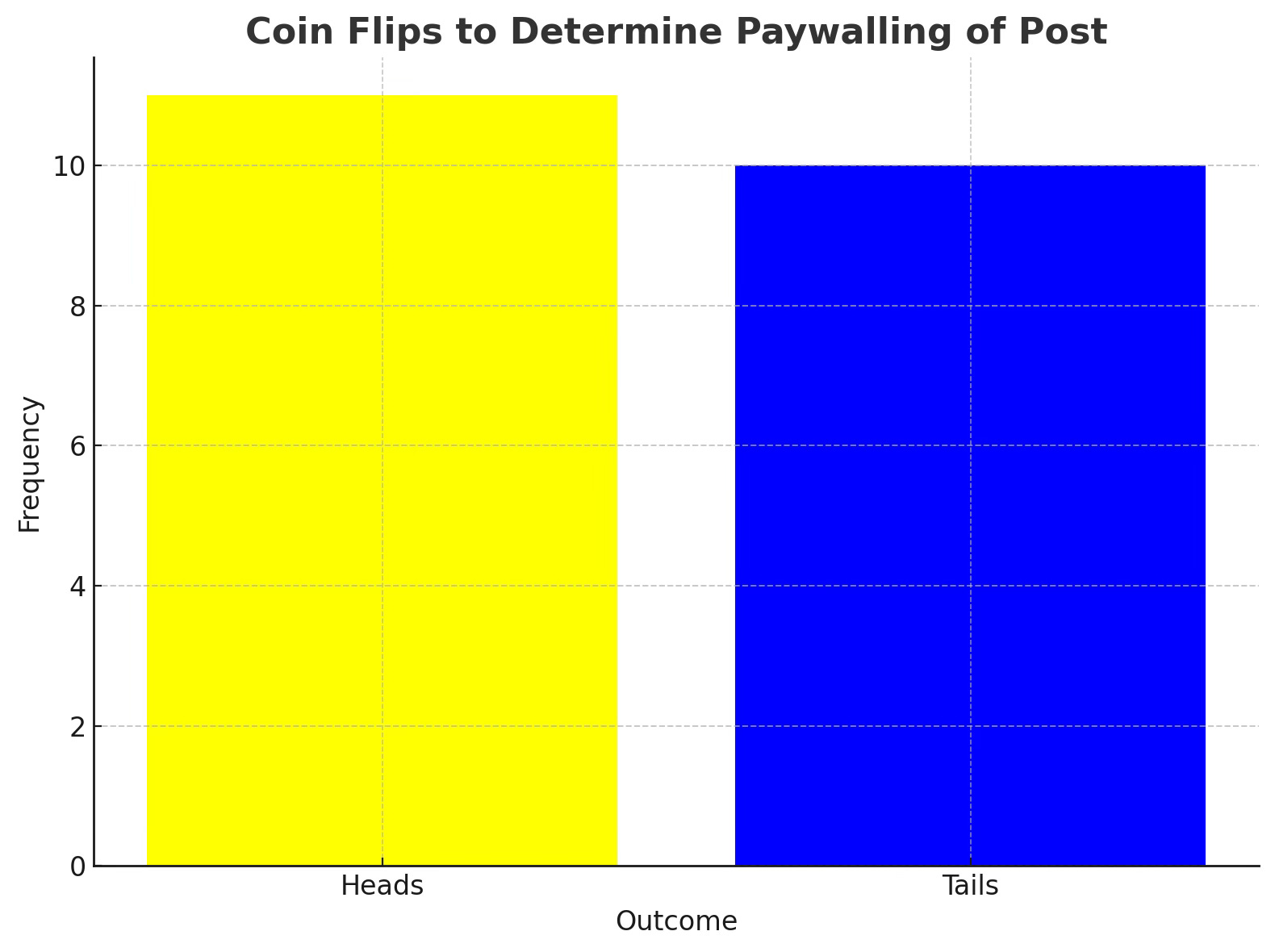
Heads wins by a single coin! What are the odds!
Okay, well here’s what you’re going to miss out if you aren’t a subscriber. I’m going to basically show you why you shouldn’t consider the state level data a robustness for the county level data, first of all, because with heterogeneity treatment effects mean treatment effects can be different (1) using a dataset of 1,000,000 people, (2) using a state-level dataset, and (3) using a county-level dataset.
Second, the simulation is so simple that I think it actually will help us really cut through the noise so that we better understand the first step in my diff-in-diff checklist: when the researcher is doing their project, they have to take a stand not just the level at which the treatment occurred. They have an even more basic task. They have to decide which target parameter they want to know the answer to. Is it ATE or the ATT or the ATU? And given we get data at different levels of aggregation, which target parameter will also be different depending on the aggregation, and if you’re not careful, you can very easily end up going after the target parameter than you were never interested in. I literally cannot think of anything worse in the world than going after one target parameter and getting a different one all because you were working with a different aggregated dataset than you though! Well, no I can think of several worse things, but on that list of things that are not good, it’s in there.
So, consider becoming a subscriber and supporting the substack. Not because you’re doing me any favors — do it for yourself! :)
