

Generative AI and Worker Productivity
Reviewing an RCT and a Staggered Diff-in-Diff


I was feeling a little sleepy last night after dinner and for some reason decided to go to sleep at 8:30pm, which is almost always a bad sign as it never seems to work out. I was hoping that I might be able to sleep all night and wake up refreshed, but what happened instead was I woke up at 11:30 with a crick in my neck. I’ve laid here for a while, thinking about how I was hoping to have made more progress on this new continuous diff-in-diff paper by Callaway, Goodman-Bacon and Sant’Anna, but alas I just can’t seem to sit down and focus long enough to do it. Still, it’s Wednesday, and I am trying to keep a schedule, and so I thought what I would do since it’s 2:40am and I’ve got insomnia is I might as well as write up a simple discussion of two papers on the causal effects of generative AI on worker productivity. One of them is an RCT, and probably you’ve seen it so I won’t say much. The other is a staggered diff-in-diff. I’ll just make random comments, I’m sure, as I write this.
The RCT
The RCT I’m referring to was by professors at Penn, MIT and Harvard as well as the Boston Consulting Group. You most likely saw it, so I will be brief, though here is a link to the working paper. Ethan Mollick, who has a forthcoming book in April on AI, is one of the coauthors on the study, and he did a substack on it a while back. I won’t be able to improve on it, so consider this just my quick refresher to lead into this other paper. Here’s that substack, but let me sort of lay out my big picture first.

Generative AI creates content that mimics intelligent human speech, but it also may even help generate new ideas. You could say, though, that it mimics human creativity across many different media, including now video. Many have said it will impact jobs, but how and which ones is very speculative. To say we know nothing isn’t exactly true, but it’s almost true. We may have to see this one played out first to know, but I suspect many of us will need to dust off our old micro theory notes about production functions and how isoquants bend or don’t at higher levels of output and with changes in technologies to even talk about our predictions.
I’m not a historian, so take this with a grain of salt, but it would seem that you could say the first machine age during the Industrial Revolution had a large impact on labor involving physical tasks as opposed to cognitive tasks. The 20th century saw technologies enhancing the productivity of the cognitive worker, too, but I don’t think it’s probably correct we saw it outrightly replacing the cognitive worker in the same way we did see it replacing the physical worker in the 1700s and 1800s. Of course it’s more complicated than all that, but to tell this story, I wanted to nonetheless maybe impress that one could argue that the first machine age did select more on physical tasks but this newer AI age is selecting more possibly on cognitive ones.
That is what makes this RCT don’t by Ethan Mollick and his collaborators at MIT, Harvard and Boston Consulting Group so interesting. The field experiment was to randomly assign the vanilla version of ChatGPT-4 ($20/month version) to consultants. Around 750 consultants, constituting 7% of the individual consultants at Boston Consulting Group, were randomized to one of three arms: nothing, ChatGPT-4, and ChatGPT-4 with some minimal tutorials explaining prompting. As there’s no difference that I saw between the ChatGPT-4 alone versus ChatGPT-4 with some training, I’ll usually just talk about the ChatGPT-4 versus nothing comparison. The experimenters then created a fictional yet realistic sneaker client and had them perform a variety of tasks like they normally would. They write:
Participants responded to a total of 18 tasks (or as many as they could within the given time frame). These tasks spanned various domains. Specifically, they can be categorized into four types: creativity (e.g., “Propose at least 10 ideas for a new shoe targeting an underserved market or sport.”), analytical thinking (e.g., “Segment the footwear industry market based on users.”), writing proficiency (e.g., “Draft a press release marketing copy for your product.”), and persuasiveness (e.g., “Pen an inspirational memo to employees detailing why your product would outshine competitors.”).
But you can get the full list of the tasks in Appendix A if you want to see it yourself. If you’ve seen the press of the study, you will know that they divided up the tasks into things which were “inside the frontier” of tasks that they thought AI could help with, and those which were “outside the frontier” of tasks that they thought AI could not help with. Interestingly, the more creative things were inside the frontier, and things like performing basic math calculations were outside. Though now with python integrated into ChatGPT-4, maybe even those things are inside the frontier.
What’s interesting to me is that the experiment is performed on high skill workers. Presumably, the consultants at Boston Consulting Group would qualify as high skill. They are college educated, highly compensated, working on different kinds of business environment tasks for a client. So this experiment that is performed is to investigate the impact that having ChatGPT-4 in the course of your work has on high skill worker productivity.
The takeaway is summarized in this graph. This particular image is from Ethan’s substack that I linked to above, but it’s also their Figure 2 from page 28 (without the arrows and the overlaid words). The control group had a mean quality score just over 4.1 and both treatment arms were more or less the same at around 5.75. Table 1 finds an average treatment effect for both treatment arms of around 1.6 to 1.75 on their quality scale.
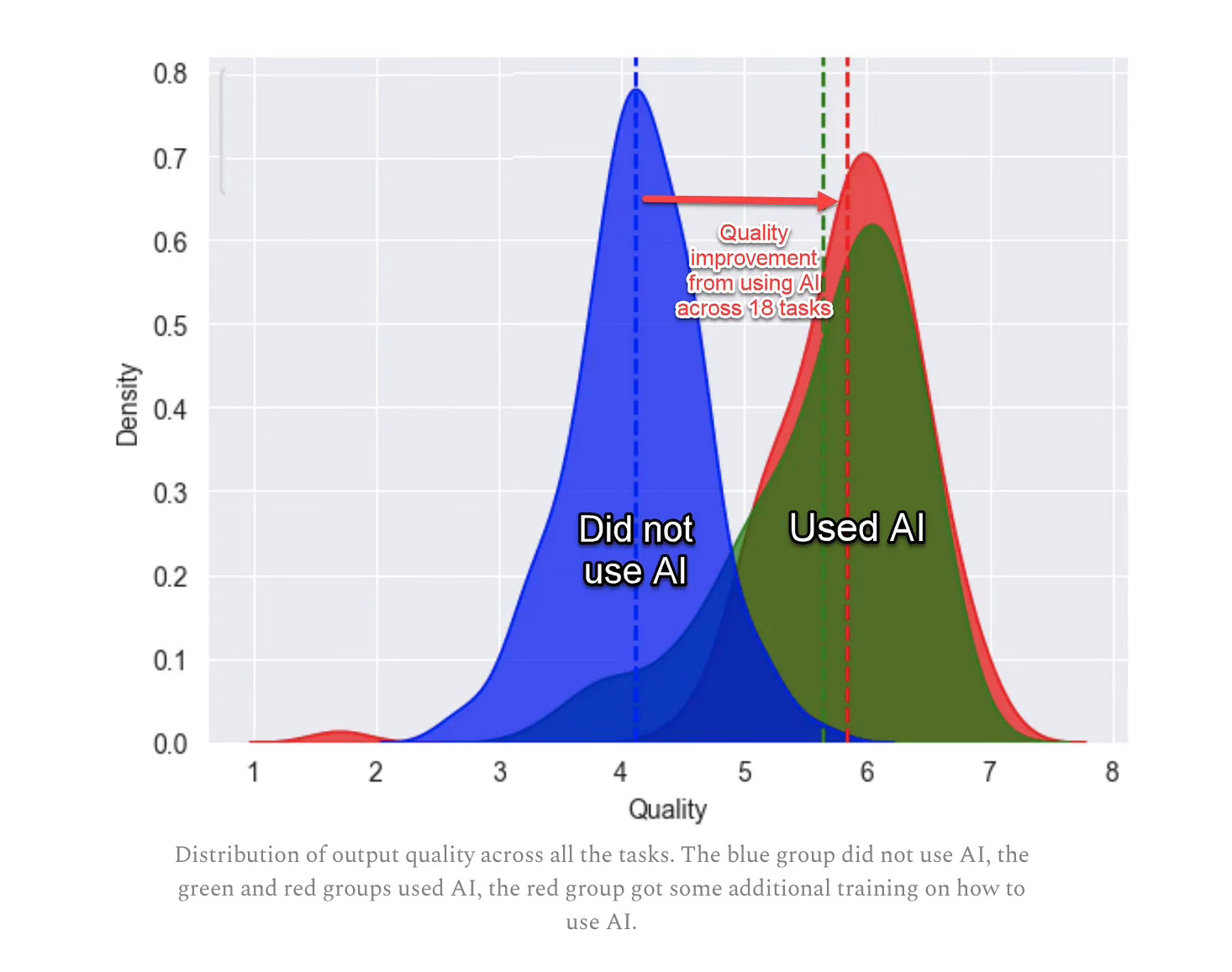
Some other results besides “quality” are worth mentioning. For the “inside the frontier tasks”, ChatGPT-4 caused workers’ task completion (measured as percent of questions answered correctly) to increase 11%. The amount of time it took to complete these various tasks fell by 1100 seconds, or almost 20 minutes.
Those tasks “outside the frontier”, meaning things they thought AI would not help with, did indeed show that some work was made worse, though. These start in Table 4. Human graders graded the correctness of certain tasks and found a 24pp reduction in correctness. There were other such negative effects, too. This is why the authors call generative AI the “jagged technological frontier”. When the tasks lie inside the frontier, there are large productivity increases. When they are outside it, though, it reverses.
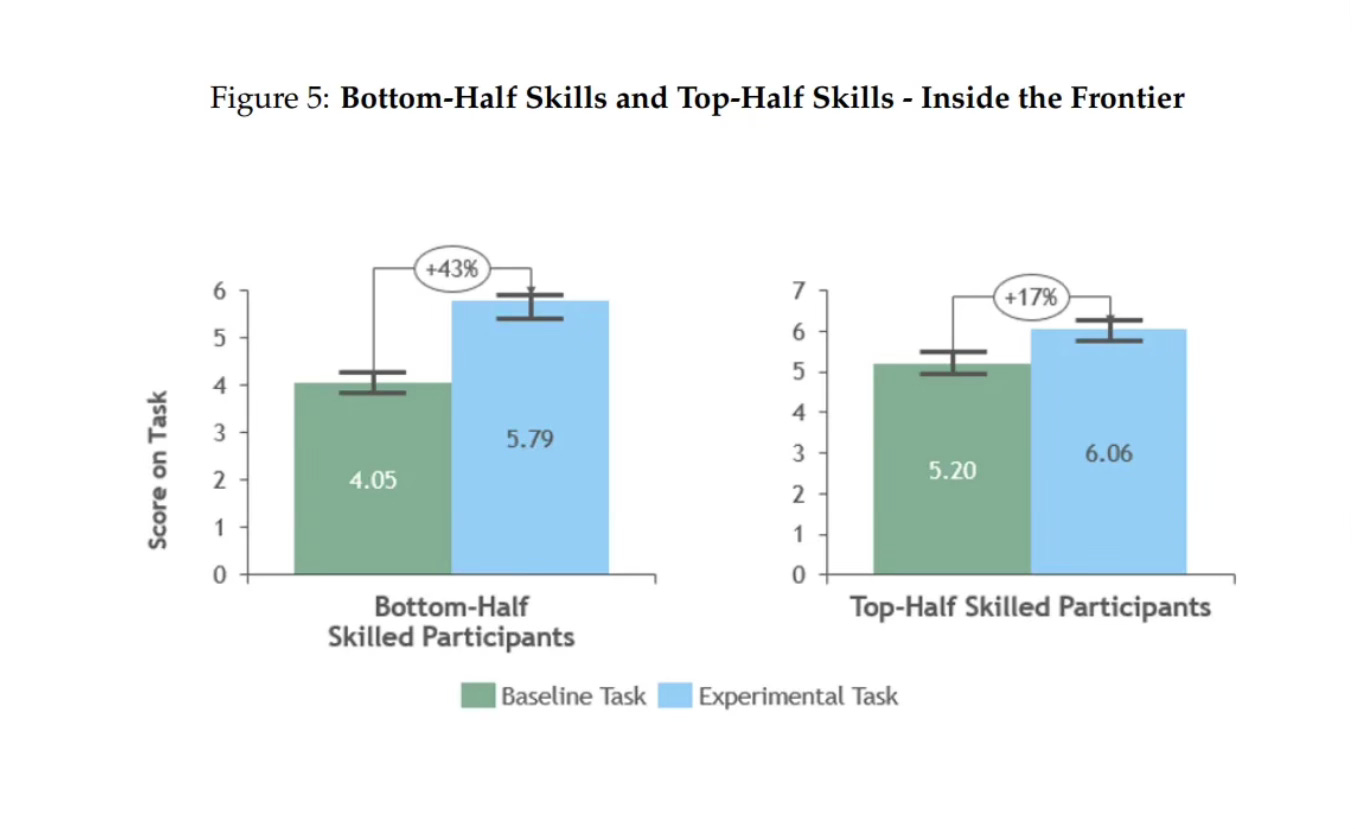
Still, even the impacts within the frontier merit close attention as there are heterogenous treatment effects by worker skill. Not all of the consultants are at baseline equally skilled at their jobs. They break it up into two groups: the bottom half have a mean baseline task score of 4.05 and the upper half have a baseline score of 5.20. What’s interesting here is the differential impacts on worker performance by skill group. ChatGPT-4 caused a 43% increase in productivity (measured by scores on tasks) for the lower half and a 17% for the upper half. But if you look below closely — ChatGPT-4 basically made the bottom-half workers more productive than the top-half skilled participants at baseline (5.79 versus 5.20). But even more than that, ChatGPT-4 basically equalized both bottom and top half participants production (5.79 vs. 6.06).
Staggered Diff-in-Diff
The second paper is by economists Erik Brynjolffson, Danielle Li and Lindsay Raymond. It’s currently an NBER working paper entitled “Generative AI at Work” and was posted in 2023. It already has almost 200 cites. This study is about a chatbot that was rolled out to an unnamed firm from October 2000 to May 2021. As this predates ChatGPT 3.5 (released in the fall of 2022), it is likely an early large language model fueled chatbot that is very different from the kind of chatbots we are seeing developed now.
