

Illustrating the bias of TWFE in event studies
Pretty little horrible pictures!

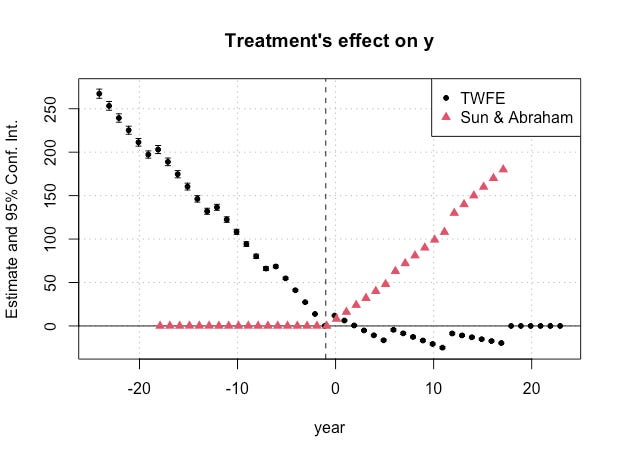
Introduction
The last few years in empirical micro and the broader quant social sciences has been a little stressful because of a series of papers by econometricians focused on the popular "difference-in-differences" design. Even Netflix uses that design. People may prefer A/B tests, but for some things, it's not feasible or realistic. Uber may not be ab…
Keep reading with a 7-day free trial
Subscribe to Scott's Mixtape Substack to keep reading this post and get 7 days of free access to the full post archives.