

Vertical regression and selection bias in diff-in-diff (plus some pictures of Pisa and Stresa Italy)

First part of this is pictures of Italy — namely Pisa where I was first of the week and now Stresa on Lake Maggiore where I am now. The second part is about parallel trends and how it is actually just another form of selection bias, which is to say, it is a gap in expected Y(0) only this time it is the gap in expected first differences. And I flipped a coin three times and they all came up tails so this is not paywalled.
Pisa, Italy at Sant’Anna University
I finished teaching a three day workshop of sorts at Sant’Anna University in Pisa on Wednesday and felt like it went well. I loved meeting my hosts, and was thoroughly impressed with the students who attended. And of course Pisa — what a beautiful city.

On Thursday morning, I said ciao though. I packed my suitcase for the tenth time, rolling all the shirts and pants and other stuff into tight rolls, put all my computer equipment away, checked out of the hotel and made my way to the train station.

Stresa, Italy on Lake Maggiore
I have to be in Berlin Sunday night for a two day workshop starting Monday. Which meant I had a three day gap. I couldn’t decide, and didn’t find Claude to be particularly helpful. I suppose it’s odd that I would be over here and have any gaps, but I left openings because I wanted the option to call some audibles as I learned more things about where I was. And the experience on Lake Maggiore in Arona had been so breathtaking that I decided to come back to Lake Maggiore, only this time to Stresa.
And wow is it ever pretty. It has luxurious hotels along the lake, but more old European style luxurious hotels than the modern ones. I took a long walk along the lake when I unpacked and had a bite to eat by the lake too.
I am still doing my intermittent fasting. It’s always a fight to do it when I come to Europe as all I want to do is have beer, wine, cocktails, pasta, every conceivable pastry, every piece of bread. But alas, those days are behind me. I’m basically going to eat normally when I get to San Sebastián in two weeks. For now it’s just water, and light meals, with Claude telling me approximately how many calories that was, and me learning the art of observing hunger pains without judgment, just curiosity. “Oh interesting — that isn’t pain. That’s just a burning sensation in the center of my belly”. Anyway I took these pictures at a restaurant on Lake Maggiore where I probably over ate a little and had a burger, fries and some tiramisu. I can’t say no to tiramisu.




Parallels trends is just selection bias
But now I want to shift gears and show you something with diff-in-diff. I am going to show you the parallel trends bias term and where it comes from, then I want to show you it’s actually a selection bias term and you can write it a few ways.
What is difference-in-differences? It is a research design. It is decidedly not a regression. The regression is the calculation, but a research design has two parts — the calculation and the identification assumption. And for difference-in-differences, when you make some basic design choices called “no anticipation” (i.e., the baseline outcome is the untreated potential outcome, Y(0)) and you use a never-treated comparison group so that both periods’ outcomes are Y(0) for the comparison group, then the only thing left in the calculation is a bias term called “non-parallel trends bias”. The identification assumption is that that term is equal to a zero, and that therefore the calculation has a causal interpretation called the “average treatment effect on the treatment group” or the ATT.
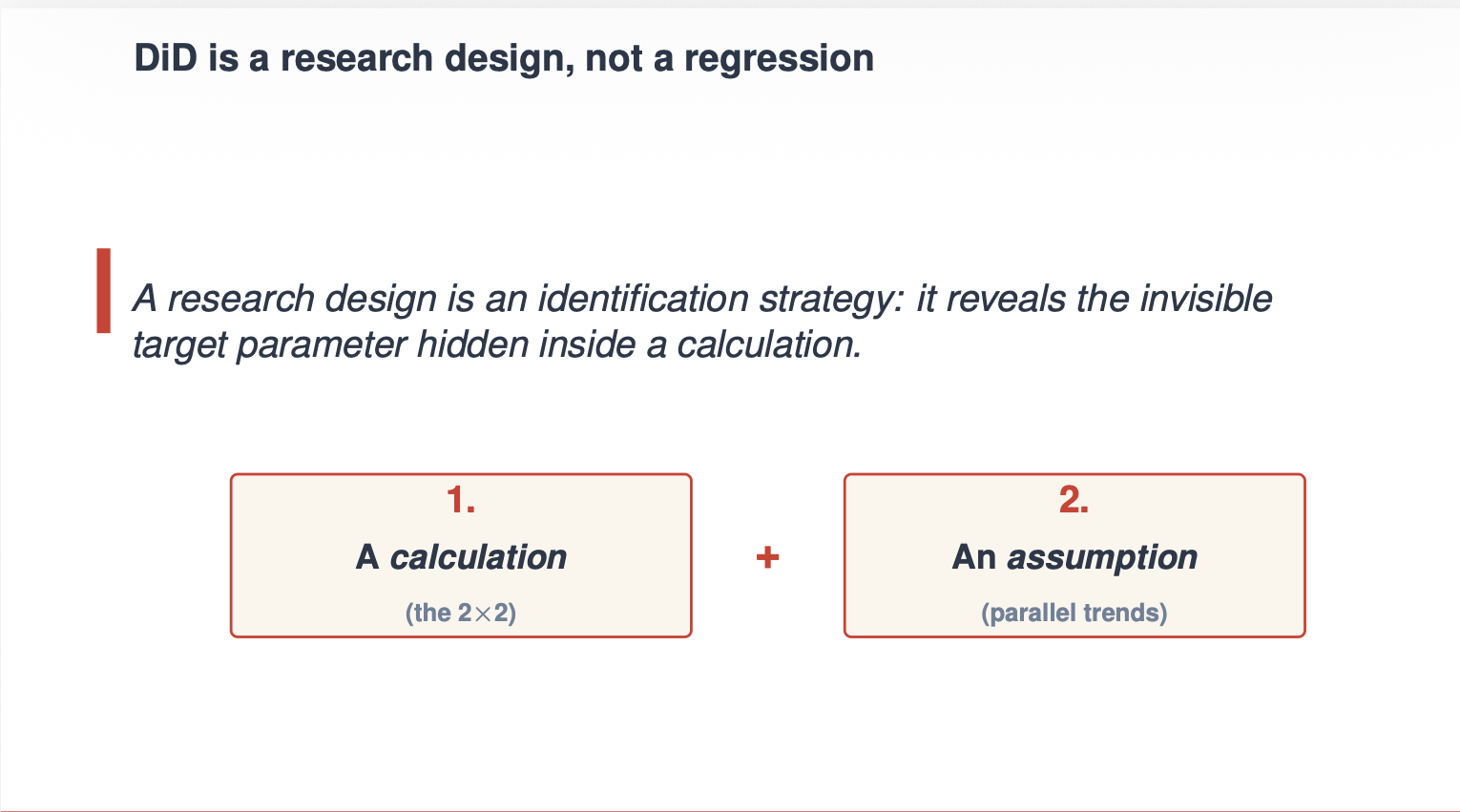
Let’s illustrate this formally by starting with the 2x2. Starting with the 2x2 is great because it helps you understand the distinction between a calculation, a causal parameter and an identification assumption. It also shows you that don’t need an event study to satisfy parallel trends. It is also the paradigm we take in our new article in the Journal of Economic Literature (with Andrew Baker, Brantly Callaway, Andrew Goodman-Bacon and Pedro Sant’Anna), “Difference-in-Differences: A Practitioner’s Guide”.
Sometimes I have been in the room when someone complains over our insistence that unless the calculation has a parallel trends assumption, that it is not therefore diff-in-diff. I always am puzzled when they say that because the 2x2 calculation is literally only biased by parallel trends! Watch and see.
Write down the 2x2 using expectations and realized outcomes
Replace realized outcomes with potential outcomes depending on whether in that period that unit was treated.
Add a zero.
Rearrange into the ATT and the parallel trends bias term

Once you assume no anticipation, which is quite trivial to enforce (you only one of three things for no anticipation to hold: the treatment to be a surprise in which case you pick the period just before treatment, the treatment to be anticipated in which you can you pick the period before it was anticipated, or the treatment effects on the future intervention in the past are zero. All three of these will let you make the substitution in step 2 of replacing the baseline outcome, Y, with the baseline potential outcome, Y(0).
And as you can see, the reason we insist that something is not diff-in-diff unless its identification assumption is "parallel trends” is because it is literally the only bias in the 2x2! And I got there in four moves — three if you don’t count rearranging terms as a move.
Selection bias is in Y(0) terms
So, it’s not controversial to say that diff-in-diff requires parallel trends. In fact, given the ubiquity and popularity of diff-in-diff, I dare say that “parallel trends” is the most widely known “identification assumption” in all of applied statistics. I mean how many people can as easily say “unconfoundedness”, “smoothness”, “exclusion and monotonicity”, or “factor models of Y(0)” compared to the number of people who can say “parallel trends”? I have to think that those are minority populations compared to diff-in-diff if only because of how common diff-in-diff is in the first place, and how easily the rhetoric of “parallel trends” is accurately presented, and how the exhibits for the evidence to support has become so commonplace and practiced (e.g., pre-trends in an event study).
But I actually am increasingly annoyed by the fact that it is called “parallel trends” because trends imply both time, and they imply it is observable, when really neither one is as accurate as I tend to want to make things. I tend to over-explain though, so probably one’s mileage may vary on this point.
If it were up to me, though, I would’ve preferred that all along we just called the non-parallel trends bias term “selection bias”. Why? Because selection bias is the difference in the mean untreated potential outcome, Y(0), for a treatment group and a comparison group. That’s what we call it in simple comparisons for instance. We don’t call selection bias in simple comparisons “equivalent levels”. We call it “selection bias” because it is a general bias, not a specific bias. Don’t believe me? Let’s go to the kung fu masters themselves — Angrist and Pischke’s classic book on causal inference, Mostly Harmless Econometrics.

I do it too in my book, Causal Inference: the Mixtape. Only I work it out even more by assuming heterogenous treatment effects.

Look at the second row in both cases: selection bias is a gap in the mean untreated potential outcome for two groups: a treatment group and a comparison group. And selection bias therefore forbids selection into treatment based on values in the Y(0) distribution.
Non-parallel trends bias is also a diff-in-diff!
Well now look back at the bias of diff-in-diff. It too is the difference in E[Y(0)] between two groups — it’s just that for diff-in-diff, the bias is the difference in two groups first difference in E[Y(0)].
But now notice a second thing. Do you see how when you compare two groups’ outcomes, E[Y|D=1] - E[Y|D=0], that its selection bias term has the same form as the original calculation? Well guess what that means — the selection bias of diff-in-diff is itself a diff-in-diff! The selection bias is “four averages and three subtractions”! The non-parallel trends bias term is a 2x2 also. It’s just that it’s a 2x2 — or a diff-in-diff — on the potential outcome, Y(0), not the realized outcome, Y.
Vertical diff-in-diff
Guido Imbens with coauthors in a few papers — I think starting at Doudchenko and Imbens, the matrix completion paper and the synth did paper — described synthetic control as a “vertical regression”. You’re comparing groups to groups, getting coefficients on the group’s comparisons across time, as opposed to within time. That’s kind of been a thing my brain struggled with for some reason. But guess what — that’s what diff-in-diff is too, and it’s what the non-parallel trends bias term is. Watch, first I’ll write down the 2x2 again.
Notice how the four terms are linear. Just like I can rearrange 5+7=12 into 7+5=12, I can do the same with that equation so I will.
That’s the same exact equation. No different. Well, Imbens and Viviano actually say something similar to this in their discussion of synthetic control too.

This equivalence between the “first differences regression” (i.e., “horizontal regression”) and the “within-time group difference regression” (i.e., “vertical regression”) is actually a general thing. But then check this out — guess what the selection bias term is for the “within-time group difference 2x2” is. You guessed it — it’s a within-time group difference Y(0) comparison.
See, it is a trend if you define a trend as any two of the possible differences in those four averages and three subtractions. But my point is a few things.
The selection bias is measured using the differences involving the post-treatment potential outcome, Y(0), not “pre-trended Y(0)”. They’re both the untreated potential outcome no doubt (under no anticipation, all pre-treatment outcomes are the untreated potential outcome by definition), but they are not the same ones that must be parallel.
The selection bias of diff-in-diff is weirdly enough itself a diff-in-diff! It is literally a 2x2! This means when you estimate a diff-in-diff, the bias of diff-in-diff is another diff-in-diff!
You can estimate 2x2s horizontally, or vertically, and in fact your TWFE is actually doing it both ways. Or rather, in the TWFE specification, they are the same thing. But if you were to do a first difference yourself and then regress that first difference on to a treatment dummy versus do a “group difference by time” and regress that onto a post dummy, that would seem to be a different regression specification but it isn’t.
Concluding remarks
So that’s it. Today I have a massage scheduled in one hour, I have to then film a podcast episode with Caitlin in a few hours, work some on my R&R, do some other work, and at some point go for a walk. I had a big breakfast at 7am, which under intermittent fasting rules means that my window will close 7+8=15 - 12 = 3:00PM. So I better go now. Enjoy your day! Next week I’ll pop back to covariates. I get so side tracked!
Also, here’s what I’m reading. The Four Loves by CS Lewis.

And Marie Howe’s What the Living Do.

Have a great day!
Scott, thank you for sharing this journey with us.
One of the things I enjoyed most about reading this post was how it felt like I was traveling alongside you. I enjoyed reading about your experiences in Italy, the places you visited, the workshops you participated in, the restaurants you explored, and the different foods you experienced along the way.
What especially stood out to me was your honesty about balancing travel with your health goals, fasting routine, and diet. I think many people can relate to the challenge of trying to maintain healthy habits while also wanting to enjoy new experiences, new cultures, and great food. It was refreshing to see that part of the journey discussed openly.
As someone who enjoys reading about other people’s experiences and reflections, I appreciated how you shared not only where you went, but also what you learned and observed along the way. Travel has a unique way of teaching us new perspectives, introducing us to different ways of living, and helping us appreciate both the differences and similarities we share with people around the world.
Thank you for taking us along on your adventure. Posts like this remind me that even when we are sitting at home reading, we can still learn something new about the world through the experiences of others.
Safe travels, and I look forward to reading about your future adventures and reflections.
💛✨